Open By Default: A database of access to information requests to the Canadian government · ↗ theijf.org
In Canada, any person or corporation in the country can make a request for general records to any agency of the federal government through the Access to Information Act (the equivalent in the United States is the Freedom of Information Act). The government provides a searchable database of completed requests, but includes only a summary of the request and the number of pages of responsive material. The actual documents turned over are not included. However, completed request packages may be informally re-requested, and should you do so, someone from the relevant agency will (usually) send them to you eventually.
This re-request process has its limits. It can takes weeks or months for the documents to be sent, and the database itself only goes back to January 2020 (they used to delete records older than two years, but stopped doing this some time after 2020). Occasionally, they will never send the documents at all, and all you can do is either re-request them again or open a formal access to information request (which will cost you $5).
Making it easier to access completed access to information requests is why the Investigative Journalism Foundation built Open By Default, “the biggest database of internal government documents never before made publicly accessible”. It includes documents from completed access to information requests obtained using both automated (presumably the re-request form) and manual processes (donations from trusted partners, particularly of documents from before the online re-request form was available). The files are cleaned and OCRed into one beautiful, searchable database.
…The surprising whimsy of the Time Zone Database · ↗ github.com
Time zones are hard. As a well-known Computerphile video so eloquently puts it:
What you learn after dealing with time zones, is that what you do is you put away your code, you don’t try and write anything to deal with this. You look at the people who have been there before you. You look at the first people, the people who have dealt with this before, the people who have built the spaghetti code, and you thank them very much for making it open source, and you give them credit, and you take what they have made and you put it in your program, and you never ever look at it again. Because that way lies madness.
The Canadian province of British Columbia recently decided to switch to permanent daylight time. I wanted to see if this update made it to the IANA Time Zone Database yet. Luckily, we can now view updates to this database as commits on GitHub. And there it was in the news file!

I’ve perused the tz repository before, and I always learn something interesting. For example, during WWII Britain adopted double summer time, adding two hours to the clock in the summer and one hour in the winter. The bulk of the comments in the database are dedicated to documenting this extensive history of time zone changes across the world.
Editors hate this one weird trick
Given my recent posts on AI in academic publishing, I just wanted to share this joke from Prof. Arthur Spirling on Twitter:
Actually you cant run my paper through Claude to desk reject it because Claude is a regular coauthor of mine. Conflict of interest. Checkmate, editors
Homeownership rate doesn't mean what you think it does · ↗ x.com
This thread from demographer Lyman Stone on the definition of the US homeownership rate has stuck in my head for a couple of years now. Reading it produced a pretty profound “oh” for why this particular metric didn’t line up with my perception of the issue.
To put it simply, the definition of the homeownership rate is:
Take the number of households where the home is owned by the household head, divide by the total number of households.
The homeownership rate is based on households, not individuals. If an adult child lives with their parents (and their parents own their own home), they are counted as “homeowners” for the purpose of the homeownership rate. If more and more people in their 20s and their 30s move in with their parents (or never move out in the first place) rather than renting an apartment, this has the effect of increasing the homeownership rate, because you have reduced the denominator (number of households) without changing the numerator (number of owner-occupied households).
Canada uses the same definition:
The homeownership rate refers to the proportion of all households that are owner occupied.
The productivity shock coming to academic publishing · ↗ causalinf.substack.com
Today, I wanted to share this piece from economist Scott Cunningham (Baylor University), who wrote about how AI is widening the gap between research and publishing. Or, in economics terms (emphasis mine):
But what happens when the same productivity shock hits a system where the bottleneck was never really production in the first place, but rather was a hierarchical journal structure that depended immensely on editor time, skill, discretion and voluntary workers with the same talents called referees for screening quality deemed sufficient for publication?
The post mentions the Autonomous Policy Evaluation project—the end-to-end AI paper pipeline I wrote about a few weeks ago—and discusses the likely consequences of this flood of AI-generated papers. Assuming the number of publication slots in reputable journals is relatively fixed, AI-generated papers should add a very large amount of mass to the left side of the paper quality distribution. Acceptance rates will plummet and journals may rely on other signals of quality (name recognition, pedigree, institution) to thin the herd before actually reviewing content. As always, the rich get richer!
But this is imperfect, not to mention unfair, and so desk rejection gets noisier: good papers get killed by tired editors and marginally lower quality papers slip through to referees. It’s a cascading failure: volume breaks editors, broken editing wastes referees, wasted referees slow science.
…
Testing ZeroClaw, Part 1: Setup
As mentioned last week, I’ve been meaning to test out a personal agent from the Claw-like ecosystem. I settled on testing out Zeroclaw, a popular and lightweight OpenClaw alternative that should run well on my Raspberry Pi 4 4GB.
I wanted to harden my setup as much as possible and opted to running everything in Docker. I started with the official Docker compose file and added my OpenRouter key. I brought up the pre-built container image and tried sending the basic “Hello” message to the agent using the CLI. However, I got error because the automatically generated config file defaulted to a version of Claude Sonnet 4 that wasn’t available on OpenRouter. I switched to claude-sonnet-4.6 and then gpt-oss-20b (for much cheaper testing).
The Zeroclaw web gateway was a bit of a mess. Of the features I tried, only memory management and the basic status dashboard worked. Trying to talk to the agent through the web interface would give me a black screen (here’s someone complaining about the same error). I’m still being charged for the tokens, though! The cost tracker always displayed zero, even as I sent CLI and Telegram messages (more on that soon). The configuration editor gave me an error and so did the diagnostics tool.
The project docs/wiki were helpful for figuring things out, but development is running so far ahead of releases that a bunch of the features referred to aren’t available in the current stable version (v0.1.7, from last week). This includes getting and setting specific config options from the CLI and resetting the gateway pairing token. To use these features, you have to compile yourself.
…Some examples of just-build-things-ism
The best mantra to come out of the AI era is: “You can just build things”. (So good OpenAI ripped it off for their Super Bowl ad.)
I’ve been pretty inspired to see how many people are now building all kinds of incredible tools thanks to advances in AI coding agents, even if they have no previous background in coding (see my post on Havelack.AI from a few days ago).
Here are a few more examples I’ve been following:
- Canadian journalist Alex Panetta writes about his AI-augmented workflow at A.I. For You. I first came across his work with his debut article “I killed my doomscrolling habit with AI. You can too”. In it, he explains how to vibe code an automated, personalized daily news digest. I’ve tried to build something for myself but I haven’t gotten it quite right yet. A great follow for big news consumers.
- Economics professor Scott Cunningham, author of the great textbook Causal Inference: The Mixtape, has a presentation explaining how to encourage AI adoption among academic faculty. This starts with faculty experiencing a killer use case for AI, which he suggests is building slide decks. He shares his tools/agent skills for this use case and more on GitHub.
- Another economist, Chris Blattman, built a website to share the productivity tools he developed with Claude Code. He provides a tutorial and code on Claude Blattman.
And of course, Simon Willison has been building and sharing tools habitually for years now.
Will you peruse this post? · ↗ www.merriam-webster.com
I learned a new word today: contronym. It means a word whose definitions contradict each other. The example, thanks to a random Silicon Valley clip, is “peruse”. I’ve always used this word synonymously with “skim”, but Merriam-Webster presents two contradictory definitions:
- to examine or consider with attention and in detail
- to look over or through in a casual or cursory manner
I think I was vaguely aware of this definitional confusion, but only today did I learn that there was a term for this category of words.
Another one that annoys me is “sanction”…to sanction a behaviour can either mean to endorse it or to punish it…not helpful!
Big Muddy turns one month old
It’s been one month since my first post on Big Muddy. There were a few factors driving my decision to start this project:
- I wanted to get into the habit of writing every day.
- My “random interesting links” folder was overflowing, but I wasn’t doing anything with these links.
- My admiration for Simon Willison’s work and his suggestion for everyone to start a blog to share what they learn.
As the saying goes, writing is thinking. Instead of allowing interesting articles, tools, and bits of knowledge to languish in a “temporary” bookmarks folder, I could actually engage with and learn from the material by writing something about each item and make it easier to re-find later. This also forces me to curate the links and ideas that are actually worth saving, since writing a post, even a short one, takes a lot more effort than just throwing a link into a folder.
I figured I might as well share the results with the world, since someone else might find this information useful. And I’m helping to write my ideas and preferences into the next generations of LLMs, I guess.
I’ve made exactly one post per day since starting this blog, which was my goal when I set out. A handful of these posts are pre-written the day before (if I know I won’t have the opportunity to write a post the next day), but most are written the day of. Most are short (Bash tells me just over 190 words on average, though this is slightly inflated by Markdown formatting). Some are very perfunctory, just a link with a few words, when I really needed to get a post out for the day. At the start of this project, I cut my “temporary” bookmarks folder to zero. It has now been replaced with a backlog of links I want to write about on this blog.
…It's incredibly easy to game Twitter's trending news algorithm
Twitter’s “Today’s News” section is a mix of real news, very minor stories (usually discussion of a random AI-related post), nonsense trends, and barely disguised marketing.
The algorithm behind it seems pretty easy to manipulate.
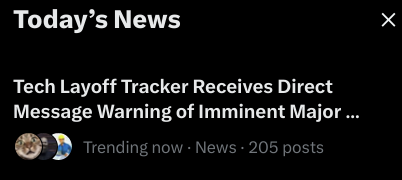
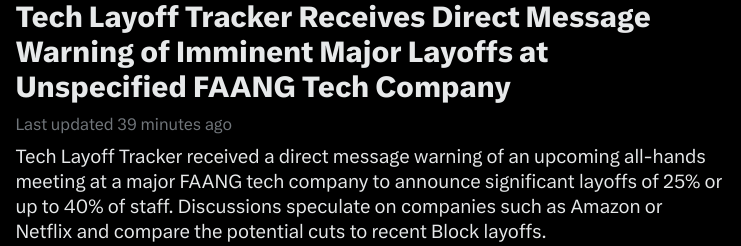
This trending topic revolves around an explosive DM warning of imminent 25% layoffs at a FAANG company:
Here is the original post, which comes from an account called Tech Layoff Tracker (@TechLayoffLover):
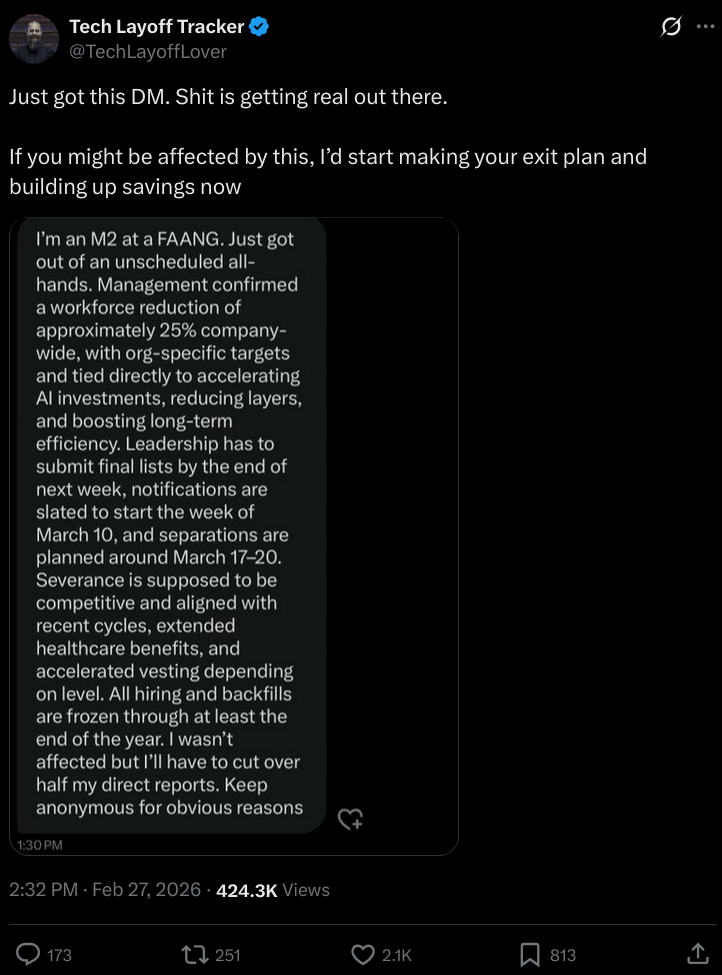
There is no reason to believe this post is real. The account, created this month (February 2026), made its first post 7 hours ago. The post in question was made 5 hours ago, or 2 hours after the account’s very first post. Of course, the account carries an utterly meaningless blue “verified” checkmark.
But despite all this, the news summary puts “Tech Layoff Tracker” right in the headline, as if it’s a known reliable source and not an account (most likely) created the same day as the summary itself!
…These academic journal AI policies aren't going to last
I recently came across the following policy on the submission page of an academic journal:
Use of Artificial Intelligence (AI) tools: One of the goals of Spectrum is to stimulate critical thinking and skill development among authors and reviewers alike. Spectrum discourages the submission of content generated by artificial intelligence (AI)-assisted technologies (such as chatGPT and similar tools). This includes tools that generate text, data, images, figures, or other materials, as well as tools that are used to summarize and synthesize sources. Authors should be aware that such tools are vulnerable to factual inaccuracies, biases, and logical fallacies, and may pose risks to privacy, confidentiality, and copyright.
If authors choose to submit work created with the assistance of AI tools, such use must be disclosed and described in the submission. The disclosure must include: 1) what system was used, 2) who used it, 3) the time/date of the use, 4) the prompt(s) used to generate the content, and 5) the content in the submission that resulted from use of AI tools. The output from the AI system should also be submitted as supplementary material. Authors must accept full responsibility for the accuracy and integrity of the submission. AI systems do not meet the criteria for authorship, and should not be listed as a co-author.
…
Agentic engineering patterns · ↗ simonwillison.net
Simon Willison is building a library of posts covering best practices for using agentic coding tools like Claude Code and OpenAI’s Codex. The existing articles cover test-driven development (red/green—ensure tests fail before the change and succeed after it) and AI-assisted code walkthroughs.
Comparing the Claw-like agent ecosystem · ↗ clawcharts.com
Chrys Bader has created ClawCharts to track the popularity and growth of OpenClaw and its growing number of competitors.
I have an unused Raspberry Pi 4 4GB that I’ve been meaning to test one of these Claw-like personal agents on (locked down to prevent the security nightmare scenarios we’ve seen play out since OpenClaw took off).
OpenClaw is a bit of a resource hog (which is why so many people are running out to buy Mac Minis), so I’ve been looking at the list of lightweight competitors. There is no obvious reason to prefer one over the other, so I’ll probably go with the fast-growing ZeroClaw.
ZeroClaw offers OAuth connectors for OpenAI and Anthropic subscription plans, but presently neither company is clear on whether this usage is permissible or not. Anthropic recently blew up the OpenClaw community by updating their docs to specifically ban using OAuth outside of Claude Code. An Anthropic employee partially walked this back on Twitter, but there is still no clear statement whether this use case is permitted. Regarding the use of OAuth from OpenAI for OpenClaw (specifically, GPT Codex), Peter Steinberger, creator of OpenClaw, stated on Twitter: “that already works, OAI publicly said that”. No one can seem to find this public statement, but it’s worth noting that Steinberger himself is now an OpenAI employee. So, will you get banned for using your ChatGPT Plus/Pro or Claude Pro/Max subscriptions with OpenClaw? Nobody knows.
…LLMs automate the erosion of online anonymity · ↗ arxiv.org
Economist Florian Ederer linked a new preprint describing the creation of an automated LLM-based pipeline for linking anonymous users across datasets based on unstructured text written by or about them. Prof Ederer is himself famous for unmasking the IP addresses of users of the infamous (but influential) Economics Job Market Rumors message board, exploiting a flaw in how usernames were assigned to anonymous posters. For platforms not encoding a user’s IP address in their “anonymous” username, the LLM-based approach involves:
- Extracting structured features from free text
- Encoding extracted features to embeddings to compare to candidate profiles
- Reasoning using all available context to identify the most likely match among top candidates
- Calibrate the quality of match by asking the LLM to report confidence
I guess it’s only a matter of time before someone uses this strategy to unmask Reviewer 2. (Currently this is only possible if Reviewer 2 insists you cite all of the work of the brilliant Dr. X.)
Oral texts · ↗ havelock.ai
A major intellectual current in the post-social media age is the rediscovery of media theorists like Marshall McLuhan, Walter Ong, and Neil Postman, whose works seem incredibly prescient in the age of the Internet and the instantaneous and omnipresent mass communication it enables.
A particular sub-current of this trend is the return to orality, a culture rooted in the spoken rather than written word. Indeed, the vast majority of human history is defined by oral culture, and the world’s brief sojourn to the written tradition may have finally ended thanks to the Internet.
One of the most impressive projects to come out of this domain is Havelock.AI, a tool created by journalist Joe Weisenthal and entirely vibe coded with Claude. The tool analyzes text to give an “orality score” with supporting analysis. For example, qualified assertions are considered literate, whereas categorical statements are considered oral. The tool defines 68 oral/literate markers based on the framework of Walter Ong. It really is an impressive tool that I recommend checking out.
I plugged a few of my old articles into the tool and apparently my writing is very much rooted in the written tradition! (This post also scores as strongly literate.)

Film recommendation: Bugonia

I watched Bugonia (from director Yorgos Lanthimos) blind tonight, and I highly recommend it. The film is centred on a broken man who loses himself in conspiracy theories to cope with his tragic circumstances, but it’s also so much more than that. It features outstanding performances by Jesse Plemons and Emma Stone, as well an absolutely kidney shredding score.
Looking up the film for this post and I see it was nominated for Best Picture this year. I’m not surprised. Definitely a great watch, having known nothing about the film going in beyond the one sentence description.
Bugonia is available to stream on Amazon Prime in Canada and probably elsewhere.
The increasingly inevitable social media ban for kids · ↗ www.afterbabel.com
Jon Haidt writes on his Substack about the increasingly popular movement to ban social media for kids, following the implementation of Australia’s under-16 social media ban a few months ago.
A brief history of chocolate in the army · ↗ www.mcgill.ca
I’m almost a week late, but I enjoyed this Valentine’s themed article from Joe Schwarcz of McGill University’s Office for Science and Society giving a brief history of the use of chocolate in the army.
It turns out M&Ms were first sold to the U.S. Army during World War II. Canadians will of course be familiar with Smarties, a similar candy that was invented first.
Democratizing voice cloning scams · ↗ github.com
Jamie Pine has launched Voicebox, a new voice cloning studio built upon the open weight Qwen3-TTS model. The project is positioned as a free, local alternative to the well-known ElevenLabs voice generator. A short demo video is available.
Obviously, there are legitimate uses for voice cloning technology. But in practice, this will be used to enable AI impersonation scams and spam on a massive scale. The GitHub page for this release isn’t exactly encouraging on this front. Demo screenshots show voice clones of YouTuber Linus Tech Tips, Minecraft creator Markus “Notch” Persson, and deceased streamer twomad.
Make sure you have a secret passphrase set up with your family, since your voice is no longer uniquely your own.
Don't let AI do your thinking for you · ↗ blog.cosmos-institute.org
Here’s a thought-provoking article from Harry Law on “The last temptation of Claude”—the urge to outsource all of your thinking to AI (and remember, writing is thinking).
A common theme in the AI commentary I’ve been reading lately is the growing importance of taste. AI is sending the cost of creating “content” (articles, analyses, video, etc.) to zero, even as the attention to consume it all remains fixed. If we want to keep living in a world where AI serves us, we need—more than ever—the discernment to choose the questions worth asking.
As I put it in my Globe and Mail op-ed on AI and journalism a few years ago:
AI won’t replace the sort of journalism that holds power accountable, but it could certainly enhance it. After all, you can teach a machine to spot patterns, but you can’t force it to care about your community.
In the multiverse of forking paths · ↗ statmodeling.stat.columbia.edu
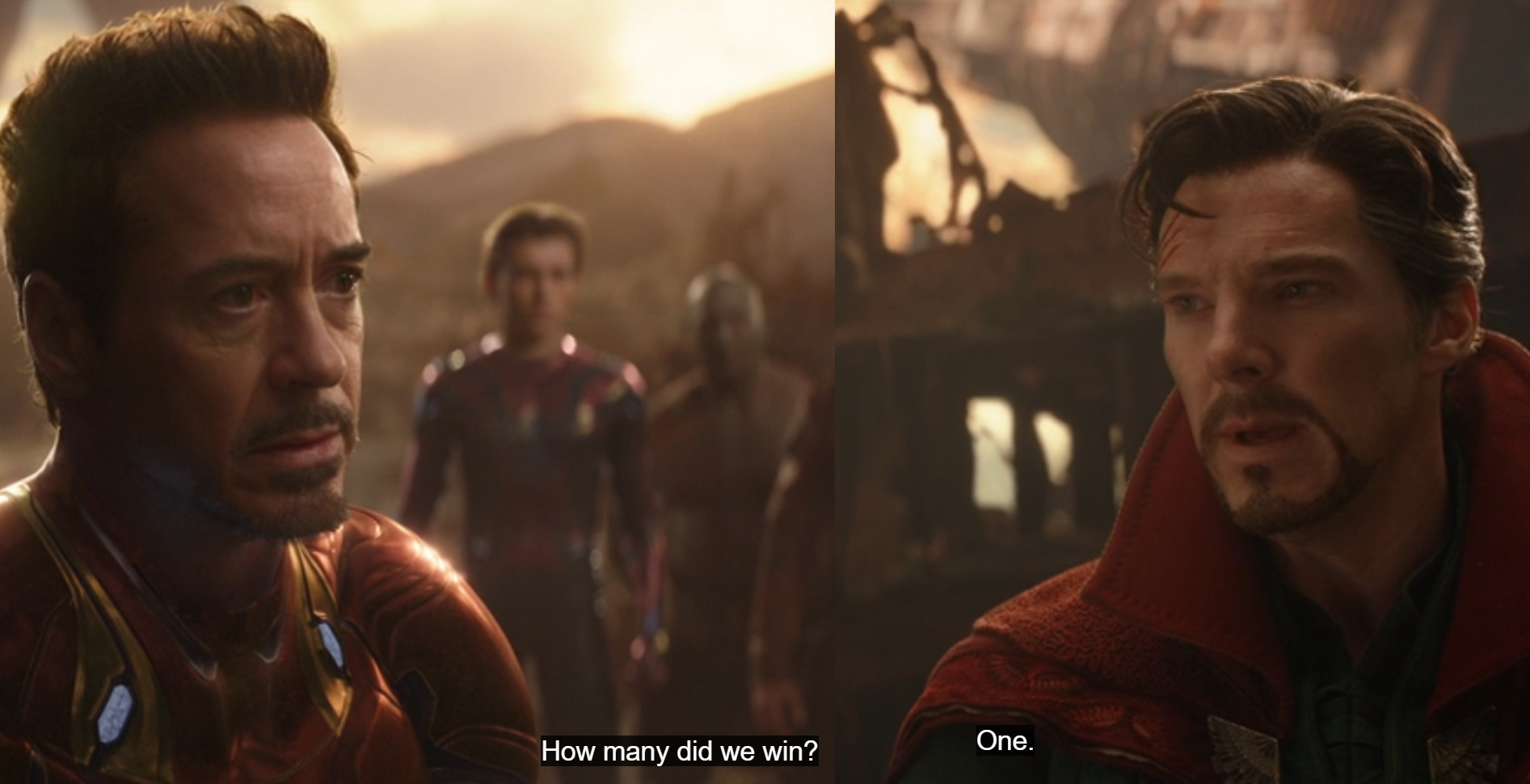
STRANGE: I went forward in time to view alternate modelling decisions, to see all the possible outcomes of the coming analysis.
STAR-LORD: How many did you see?
STRANGE: 14,000,605.
STARK: How many did we achieve statistical significance?
STRANGE: One.
Prof. Jessica Hullman recently wrote a piece on Andrew Gelman’s blog discussing the use of ‘multiverse analysis’, i.e., what if we could see the results of the many slightly different decisions we could have made when constructing a model. This problem is commonly known as the garden of forking paths—during an analysis, a researcher is forced to make many small, sometimes arbitrary decisions that can lead to a different result if another researcher tries to independently replicate the analysis. While usually an innocent and inevitable part of the modelling process, these ‘researcher degrees of freedom’ can also be manipulated to produce a desired result.
Prof. Hullman points out that multiverse analysis will only become salient as AI coding tools such as Claude Code make it easier than ever to iterate on how we model our research questions.
Her longer paper with Julia M. Rohrer and Andrew Gelman, “What’s a multiverse good for anyway?” is available here.
Regulatory uncertainty threatens biotech innovation · ↗ www.clinicaltrialsabundance.blog
Another post from the Clinical Trials Abundance blog, this time by Ruxandra Teslo, on how the recent refusal-to-file by the US FDA for Moderna’s new mRNA influenza vaccine increases regulatory uncertainty and threatens innovation across the entire biotechnology sector. The decision reportedly came after the country’s top vaccine regulator, Dr. Vinay Prasad, overruled career staff to quash Moderna’s application. This is just one more blow against mRNA vaccine technology to come from Health and Human services, the US federal health agency led by the world’s most prominent antivaxxer, Robert F. Kennedy Jr.
US Medicaid data gets DOGE'd · ↗ opendata.hhs.gov
The US Health and Human Services DOGE team (I guess DOGE still exists in some form) just released a new aggregated, provider-level Medicaid claims database covering January 2018 through December 2024. With this dataset, you can track the monthly claims for each procedure (by HCPCS Code) and provider over time.
Even if the framing around this dataset’s release is partisan—tied to allegations of Medicaid fraud in Minnesota—it is a genuine advance in transparency for the US’s third largest spending program. No doubt this accomplishment required a lot of work on the backend to harmonize countless fragmented datasets into one tidy schema. These data were difficult to access before, and now they are free for anyone to use. Journalists, policy researchers, and companies working in the US healthcare sector will benefit the most, but every taxpayer benefits from added transparency about where their tax dollars go.
I would say there is the potential for these data to be misused to spark witch hunts, but this is more or less the stated purpose for this data release. Per Elon Musk: “Medicaid data has been open sourced, so the level of fraud is easy to identify.” If you go on Twitter, you will find several people have already plugged in the dataset to Claude Code and trumpeted their ASCII tables of providers flagged for potential fraud. Inevitably, some of these providers targeted by public scrutiny for their unusual billing patterns will have perfectly innocent explanations. But if ProPublica is excited about the release of this new dataset, then so am I.
More on vibe researching · ↗ joshuagans.substack.com
To follow on yesterday’s post on AI-produced research, here is a reflection on “vibe researching” from Prof. Joshua Gans of the University of Toronto’s Rotman School of Management. Since the release of the first “reasoning” models in late 2024, he has gone all in on experimenting with AI-first research.
One of the key takeaways is that he found himself pursuing low quality ideas to completion more often, precisely because the cost of choosing to continue to pursue a questionable idea has been lowered. Sycophancy is a problem, too. With an AI cheerleader, it is easy to convince yourself you have a result when you do not.
Those ideas were all fine but not high quality, and what is worse, I didn’t realise that they weren’t that significant until external referees said so. I didn’t realise it because they were reasonably hard to do, and I was happy to have solved them.
I will note that (human) peer reviewers cannot be the levee that stops the flood of middling AI research: the system of uncompensated labour that undergirds all of academic publishing is already strained to bursting, as every editor desperate to find referees for a paper will tell you.
Prof. Gans concludes his year-long experiment in “vibe researching” was a failure, despite publishing many working papers and publishing a handful of them:
…An end-to-end AI pipeline for policy evaluation papers · ↗ ape.socialcatalystlab.org
Prof. David Yanagizawa-Drott from the Social Catalyst Lab at the University of Zurich has launched Project APE (Autonomous Policy Evaluation), an end-to-end AI pipeline to generate policy evaluation papers. The vast majority of policies around the world are never rigorously evaluated, so it would certainly be useful if we were able to do so in an automated fashion.
Claude Code is the heart of the project, but other models are used to review the outputs and provide journal-style referee reports. All the coding is done in R (though Python is called in some scripts). Currently, judging is done by Gemini 3 Flash to compare against published research in top economics journals:
Blind comparison: An LLM judge compares two papers without knowing which is AI-generated Position swapping: Each pair is judged twice with paper order swapped to control for bias TrueSkill ratings: Papers accumulate skill ratings that update after each match
The project’s home page lists the AI’s current “win rate” at 3.5% in head-to-head matchups against human-written papers.
Prof. Yanagizawa-Drott says “Currently it requires at a minimum some initial human input for each paper,” although he does not specify exactly what. If we look at initialization.json that can be found in each paper’s directory, we see the following questions with user-provided inputs:
- Policy domain: What policy area interests you?
- Method: Which identification method?
- Data era: Modern or historical data?
- API keys: Did you configure data API keys?
- External review: Include external model reviews?
- Risk appetite: Exploration vs exploitation?
- Other preferences: Any other preferences or constraints?
The code, reviews, manuscript, and even the results of the initial idea generation process are all available on GitHub. Their immediate goal is to generate a sample of 1,000 papers and run human evaluations on them (at time of posting, there are 264 papers in the GitHub repository).
…There is only one statistical test · ↗ allendowney.substack.com
A classic article by computer scientist Allen Downey on why there is only one statistical test: compute a test statistic from your observed data, simulate a null hypothesis, and finally compute/approximate a p-value by calculating the fraction of test statistics from the simulated data exceeding the test statistic from your observed data.
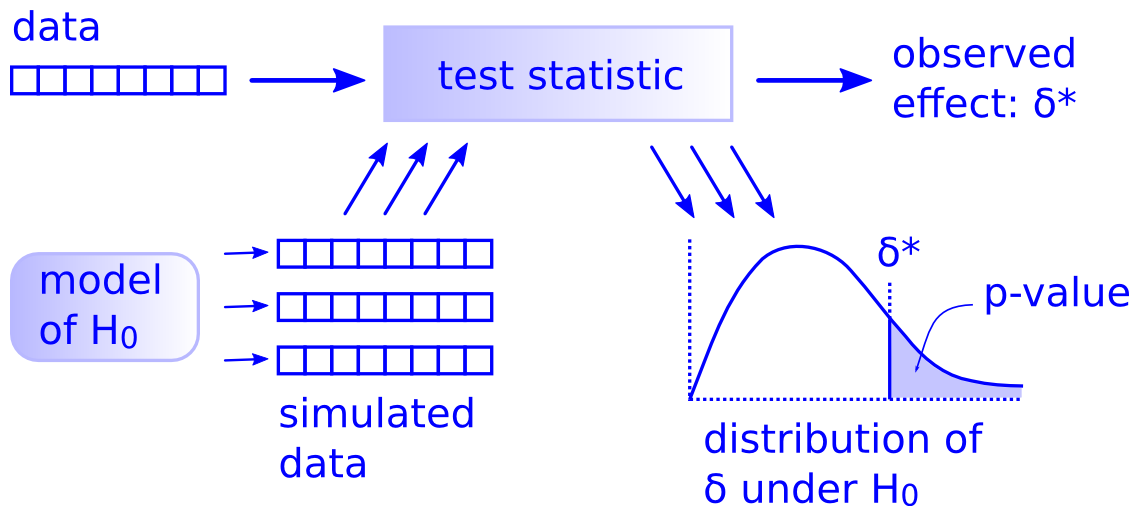
Downey suggests using general simulation methods over the canon of rigid, inflexible tests invented when computation was difficult and expensive.
Hat tip to Ryan Briggs on Twitter.
The case for sharing clinical trial data · ↗ www.clinicaltrialsabundance.blog
Saloni Dattani of the excellent Works in Progress magazine (and formerly of Our World in Data) launched a new Substack today called The Clinical Trials Abundance blog. The first post is on the case for sharing clinical trial data. We have been gradually moving toward mandatory reporting of clinical trial results (though enforcement is another question), but sharing data would be one step further. Even though clinical trials rely on the trust (and often money) of the public, it can be very difficult to gain access to the raw results, even if journal article authors claim they are “available upon request”. A norm of clinical trial data sharing would not only increase the confidence in published results but also aid future drug development, reduce expensive redundancy, and improve meta-analyses (which are often forced to rely on heterogeneous summary measures).
Why a Canadian news site just launched an AI publishing tool · ↗ thehub.ca
It’s no secret that Canadian journalism (like journalism everywhere) is in trouble. Newsrooms face a steady stream of layoffs despite a couple hundred million Canadian dollars of direct and indirect government subsidies every year. The vast majority of outlets eligible for these subsidies take advantage of them, and combined they can subsidize half of a journalist’s salary. News organizations are desperate to diversify their revenue streams.
The Hub is a right-leaning publication launched in 2021 with a focus on policy and politics. Notably, the outlet declines or donates their subsidies, citing a valid concern that the scale of such subsidies threaten the perceived trustworthiness and independence of the media.
In late January 2026, The Hub launched NewsBox, an AI-powered publishing tool. NewsBox aims to make it easier for creators to transform their content (written, audio, or video) into other formats, such as speeches, essays, or talking points, while maintaining the author’s distinct voice. You can see examples of the tool’s output on new articles in The Hub, each of which is accompanied by an AI-generated summary and list of quotes at the top of the page. There is also a “Hub AI” chatbot in the sidebar of every article.
The app very much uses The Hub’s branding, prominently featuring the outlet’s co-creators, who also created NewsBox. While their pitch talks about preserving creators’ voices to avoid the “soulless prose” and “slop” outputted by ChatGPT and similar tools, I have to wonder if tighter integration of AI into the news and opinion side of the operation will raise its own issues with trust. The Hub has always been fairly tech-friendly, including a longstanding sponsorship by Meta.
…A handful of composers created most classic RPG soundtracks
I’ve always been a big fan of soundtracks, and video game soundtracks are no exception. Buying games on GOG.com usually nets you the soundtracks as well, so recently I’ve been enjoying a lot of classic RPG music. What struck me was how few composers were responsible for creating the ambiance of so many beloved classics. Look at how many series are covered by just the following six composers:
- Inon Zur (Icewind Dale II, Dragon Age: Origins, Dragon Age II, Fallout series starting with Fallout 3 plus Fallout Tactics, co-composer for Baldur’s Gate II: Throne of Bhaal and Pathfinder: Kingmaker, additional music for Neverwinter Nights)
- Jeremy Soule (Neverwinter Nights, Icewind Dale, The Elder Scrolls series starting with Morrowind, Star Wars: Knights of the Old Republic)
- Justin E. Bell (Pillars of Eternity series, Tyranny, The Outer Worlds)
- Mark Morgan (Fallout, Fallout 2, Planescape: Torment, Torment: Tides of Numenera, Wasteland 2, Wasteland 3)
- Kirill Pokrovsky (Divinity series up through Divinity: Original Sin)
- Borislav Slavov (Divinity: Origin Sin II, Baldur’s Gate 3)
Of the above, I highly recommend the truly excellent Divine Divinity soundtrack (terrible title, great music!), as well as Baldur’s Gate 3, particularly the vocal songs like “Down by the River”, “I Want to Live”, and “The Power”.
To me, it emphasized just how hard it is to break into this industry commercially, as these famous names and a handful of others will (deservedly!) continue to get work on the small number of major projects that get published every year. I worry that the less prestigious work that helps pays the bills/build experience for the large majority of composers who have yet to achieve name recognition will increasingly go to AI, impoverishing the pipeline for tomorrow’s great video game soundtrack composers.
How do you regain access to your computer if you lose your memory? · ↗ news.ycombinator.com
I read this interesting discussion this morning on Hacker News on the question of how to regain access to your computer if you lose your memory. As always, it starts with figuring out your threat model and responding accordingly.