How to avoid cognitive surrender to AI · ↗ alexpanetta.substack.com
I am sharing a thoughtful article today from Alex Panetta’s A.I. For You on avoiding over-reliance on AI: “cognitive debt”, “epistemic debt”, or “cognitive surrender”.
A particularly interesting nugget regarding the “Your Brain on ChatGPT” article from the MIT Media Lab (yes, that MIT Media Lab):
The paper is even written to get LLMs to read it carefully. The paper carries instructions telling LLMs which section to read first, which appears to be a clever way to force relevant context atop the context window, as LLMs tend to best remember the beginning and end of conversations — not the middle.
Opt out of very new Python package versions with uv
In light of several recent Python package compromises (litellm, telnyx), here is a useful tip from Hacker News commenter mil22:
For those using uv, you can at least partially protect yourself against such attacks by adding this to your pyproject.toml:
[tool.uv]
exclude-newer = "7 days"or this to your ~/.config/uv/uv.toml:
exclude-newer = "7 days"This will prevent uv picking up any package version released within the last 7 days, hopefully allowing enough time for the community to detect any malware and yank the package version before you install it.
Commenter notatallshaw follows up with how to achieve similar behaviour in *pip*:
Pip maintainer here, to do this in pip (26.0+) now you have to manually calculate the date, e.g. –uploaded-prior-to="$(date -u -d ‘3 days ago’ ‘+%Y-%m-%dT%H:%M:%SZ’)"
In pip 26.1 (release scheduled for April 2026), it will support the day ISO-8601 duration format, which uv also supports, so you will be able to do –uploaded-prior-to=P3D, or via env vars or config files, as all pip options can be set in either.
Colorado advances ban on algorothmic price and wage discrimination · ↗ coloradonewsline.com
The Colorado House voted today to ban the use of personal data to algorithmically set the price of a product or determine a wage. The legislation will now advance to the Colorado Senate for consideration. The summary of the bill, HB26-1210, reads:
Surveillance data is defined in the bill as data that is obtained through observation, inference, or surveillance of consumers or workers and that is related to personal characteristics, behaviors, or biometrics of an individual or group. The bill prohibits discrimination against a consumer or worker through the use of automated decision systems used to engage in:
- Individualized price setting based on surveillance data regarding a consumer; or
- Individualized wage setting based on surveillance data regarding a worker.
Obviously, the bill enumerates exceptions to the above rules, as it is not intended to ban, for example, charging a customer more to deliver an item a longer distance nor to prohibit schemes like discounts for students or seniors. One of the challenges of writing laws like this is to ensure they are written narrowly enough to target dystopian hyper-individualized pricing based on tracking of Internet and phone activity rather than normal business practices like pricing insurance policies according to demographic risk factors.
Colorado is one of at least a dozen American states considering similar bans. I don’t believe any of these proposed broad-based bans have been signed into law yet. I wrote about algorithmic price discrimination (surveillance pricing) last week in the context of proposed legislation in the Canadian province of Manitoba.
How SARS-CoV-2 variants get named on GitHub · ↗ github.com
Bioinformatics has long been an unusually collaborative and transparent field, with genomes, protein structures, and other complex biological data habitually deposited into open databases during the course of research. The situation was no different at the outset of the COVID-19 pandemic, when a small group of scientists developed the Pango nomenclature for classifying variants of the SARS-CoV-2 virus. Outside of a handful of Greek-letter “variants of concern” names assigned by the World Health Organization, the Pango nomenclature is the standard for tracking the evolution of the SARS-CoV-2 virus. You may recall names such as B.1.1.7 (Alpha or the UK variant), B.1.351 (Beta or the South African variant), and P.1 (Gamma or the Brazilian variant). You can see a complete list of active SARS-CoV-2 lineages using the Pango nomenclature here.
By August 2020, the work of defining new lineages of SARS-CoV-2 had moved to GitHub, where the scientific process could happen in transparent and collaborative way. The definition of new lineages happens on proposals submitted as GitHub issues. In May 2023, a second GitHub repository was opened to move discussions of smaller or less clear lineages out of the main repository. These discussions can be promoted to the main repository, as this issue tracking LP.8.1 sub-lineages was in May 2025.
The work of defining new lineages of SARS-CoV-2 continues to this day on the GitHub repository, as the virus continues to mutate and evolve. And bioinformatics continues to be a shining beacon for open science for the rest of us to learn from.
Prediction markets are coming to Canada · ↗ www.theglobeandmail.com
(Archive link to this story)
Wealthsimple is a fintech company at the forefront of a lot of innovation in Canada’s personal finance sector since the company’s founding in 2014. Notably, Wealthsimple was the first broker in Canada to offer zero-commission trades, back in 2019. In 2020, they started offering the ability to trade crypto. In 2025, they launched zero-commission options trading. This year, the company received regulatory approval to bring prediction trading to Canada.
Unlike in other parts of the world, prediction markets have not flourished in Canada and have been considered basically illegal since a 2017 ruling from Canada’s federal securities regulator. Wealthsimple has been able to get around this ruling by only offering contracts on a narrow set of questions:
Despite a 2017 ruling that largely banned these kinds of short-term, yes-or-no contracts, certain regulated firms that are CIRO members are able to offer certain types of “event contracts,” […] The approval for Ontario-based Wealthsimple permits it only to offer contracts tied to economic indicators, financial markets and climate trends, the company confirmed – not sports or elections, which are among the most popular uses of prediction markets in the United States.
Wealthsimple has driven innovation in the Canadian personal finance sector; however, their new product offerings over the last few years seem to be speedrunning the Robinhood trajectory toward high-risk, high-volatility trading and away from their traditional niche of broad, diversified funds/ETFs for ordinary people to set-and-forget. This pivot can be understood as part of a broader trend toward the casinofication of everything, which took off with crypto and the legalization of online sports betting.
Will AI help Canadian police counter a tsunami of fraud? · ↗ theijf.org
Zak Vescera, writing for the Investigative Journalism Foundation, observes that fraud cases reported to Canadian police has more than doubled between 2013 and 2024:
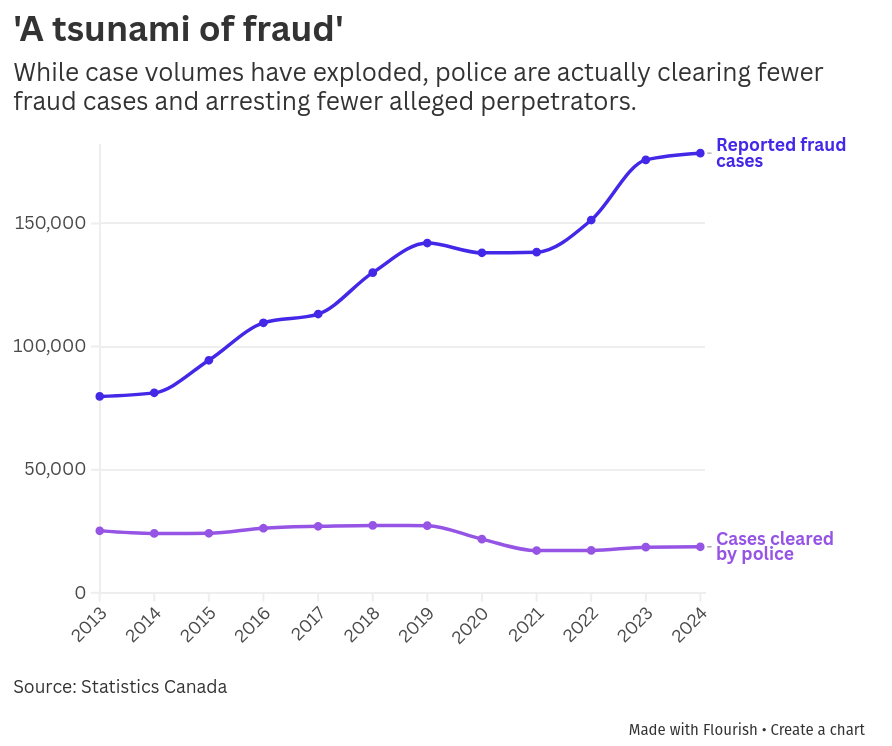
At the same time, the number of cases cleared by Canadian police has fallen. In 2013, the ratio between reported cases and cleared cases was about 3:1; by 2024, this ratio was over 9.5:1.
The vast majority of fraud cases go unsolved. This is unsurprising given that many are perpetrated over the Internet by individuals overseas and involve methods of sending money that are difficult to recover, such as crypto, gift cards, and physical transfers of cash.
In response, the National Cybercrime Coordination Centre (NC3) of the RCMP—Canada’s national police service—have built a case management system and data portal they hope will eventually be adopted by all Canadian police forces. According to the article, this system is aimed at improving coordination, data sharing, and analysis. The platform will also host a set of AI tools, though the RCMP is vague on details and which are currently implemented. The article gives a few examples: OCR allowing victims to scan gift cards used in fraud rather than typing numbers manually, a tool to classify reports to help police target their investigative resources, and a report generator to simply data sharing when investigations go international.
…Vandalism of OpenStreetMap · ↗ en.wikipedia.org
OpenStreetMap (OSM) is an open, community-driven map database powering countless apps and services and used by organizations including Amazon, Apple, Microsoft, Uber, Mapbox, and Wikimedia. In short, it is foundational infrastructure for the web. For regions with active communities (particularly in Europe), OSM is often noted for the superiority of its data on features such as cycling routes, hiking trails, and footpaths.
The Wikipedia article for OpenStreetMap documents several instances of data vandalism, which OSM is vulnerable to as a crowdsourced project. Three incidents stood out:
- In 2012, Google fired two “rogue contractors” for vandalizing the OSM database, intentionally adding false data such as reversing the direction of one-way streets.
- In 2018, a vandal made several viciously antisemitic edits to place names around New York City. While quickly reverted at the source, these changes nonetheless propagated into downstream applications pulling data from MapBox, such as Zillow, Snapchat, Citibike, and Wikipedia.
- Users of the mobile game Pokémon GO regularly vandalize the OSM database underlying the game to gain a gameplay advantage, although the authors of the research article on this subject note this vandalism tends to be transitory rather than sustained.
Side note: I was amused to note how strong Google’s regional results bias is for “OSM”—the entire first page is taken up by results related to the Orchestre symphonique de Montréal.
Properly the work of federal public health agencies · ↗ covidtracking.com
One of the reasons I started this blog was to have a place to put down posts and articles that have lodged themselves in my brain. The wind-down announcement of the COVID Tracking Project, a volunteer-led COVID-19 data tracking collaboration, is one such article.
But the work itself—compiling, cleaning, standardizing, and making sense of COVID-19 data from 56 individual states and territories—is properly the work of federal public health agencies. Not only because these efforts are a governmental responsibility—which they are—but because federal teams have access to far more comprehensive data than we do, and can mandate compliance with at least some standards and requirements.
After one year of work, the COVID Tracking Project decided to quite collecting data on COVID-19 in the United States, because they recognized that the work of collecting a comparable, national-level dataset was the responsibility of federal government agencies.
As someone who co-led the COVID-19 Canada Open Data Working Group, which curated COVID-19 data for Canada until the end of 2023, I think about this article a lot. It’s a good read, and it speaks to how essential open data was to filling in the gaps in the national and international understanding of the COVID-19 pandemic.
For map nerds only: An atlas of world history · ↗ www.oldmapsonline.org
I am sharing today TimeMap.org: an atlas of regions, rulers, people, and battles throughout history. Thoroughly enjoyable to swipe through, especially for connoisseurs of the map game genre.
Hat tip to agilek on Hacker News.
Fight club at the bird feeder · ↗ www.allaboutbirds.org
Alternate title: Blue Jay brutally feeder mogs Tufted Titmouse
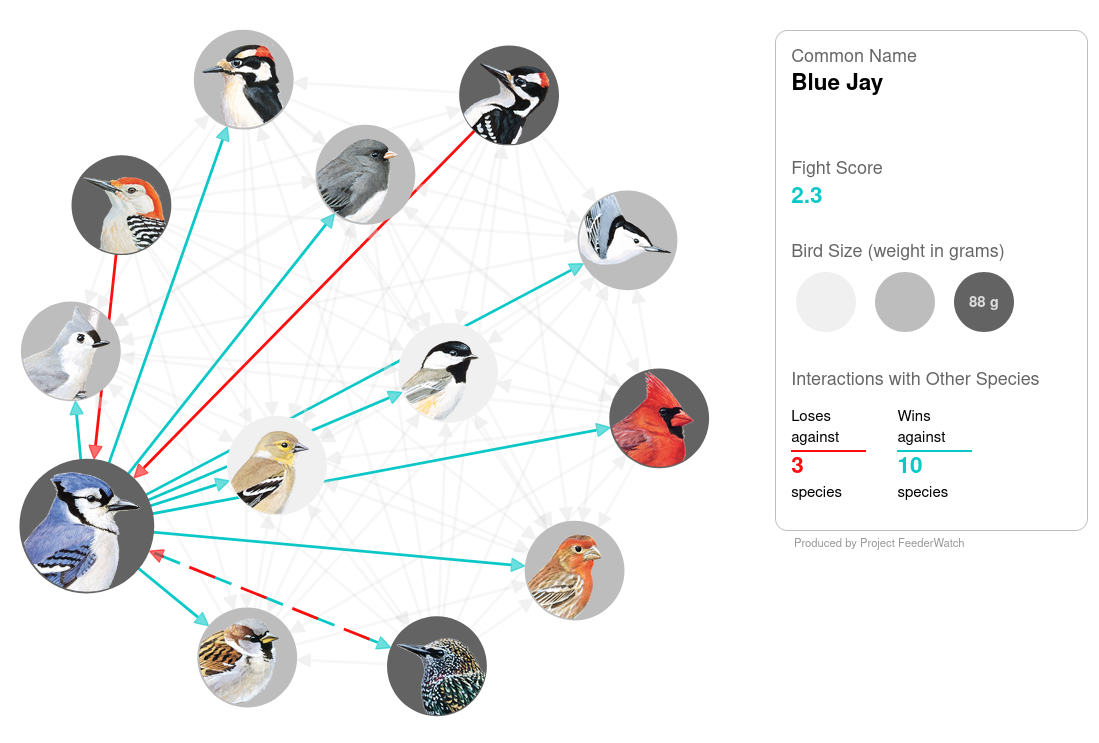
From the Cornell Lab of Ornithology, a pretty neat article about dominance hierarchies at the bird feeder using over 7,600 observations collected by citizen scientists contributing to Project Feeder Watch. Essentially, bird watchers reported instances when one bird species successfully displaced another at the bird feeder, and used this network of comparisons to build a dominance hierarchy. By using information contained within the network, you can even compare birds that are rarely observed together. Not all dominance patterns are linear, however, as the article reports:
A separate analysis uncovered some dominance triangles in which three birds had one-to-one relationships independent of each other, like a game of birdy rock-paper-scissors. For example, the House Finch dominates the Purple Finch, and the Purple Finch dominates the Dark-eyed Junco, but the junco dominates House Finch.
The full paper is here: Fighting over food unites the birds of North America in a continental dominance hierarchy.
This work is reminiscent of network meta-analysis, in which three or more interventions (e.g., drugs) are compared using both direct and indirect evidence. For example, if there are studies comparing drug A versus drug B and drug B versus drug C, we can infer the comparison between drug A and drug C, even if no study has ever directly compared them.
Make buses faster and more reliable by having fewer stops · ↗ worksinprogress.co
This fascinating article by Nithin Vejendla in Works in Progress makes the case that bus networks would benefit from bus stop balancing: having fewer stops spaced further apart. This is especially true in the United States where stops tend to be only 700–800 feet (roughly 210–240 metres) apart. While having many bus stops theoretically improves access to the transit network, it also means that buses are slower (more time is spent accelerating, decelerating, and loading/unloading passengers) and less frequent, which reduces where you can actually go in a fixed amount of time, as well increasing the variability in the time it takes to get there.
The biggest problem holding back public transit in North America is that it is unreliable, and bus stop balancing is a rare policy solution that offers improved service without having to spend more. With fewer stops, the same number of buses can complete the same route faster and with greater frequency. This stops a single missed or delayed bus from ruining your plans or forcing you to build in extra time.
A research study from my city of Montreal even gets a shout out. As a big public transit user, I avoid buses where possible in favour of the metro and walking, because these modes of transportation tend to be much more reliable and less variable when it comes to the question of “how long will it take for me to get from point A to point B”. Stop balancing could go a long way toward addressing one of the main complaints about public transit: too many routes are not frequent or reliable enough to let riders stop worrying about the schedule.
Manitoba introduces bill to ban algorithmic price discrimination · ↗ www.cbc.ca
The Canadian province of Manitoba has introduced a bill to ban algorithmic price discrimination (also known as surveillance pricing), i.e., the use of personal data to set prices for individual consumers:
New Democrats announced in December they would begin cracking down on what’s known as differential or predatory pricing. That is when retailers charge different amounts for the same products based on the timing of customer purchases, where they live or other personal data. […] The proposed legislation would render the use of “personalized algorithmic pricing,” both online or in store, an unfair business practice.
Okay, I guess there’s a lot of different names for this particular practice. Whatever we call it, I believe bills cracking down on algorithmic price discrimination will be very popular, as it constitutes a very clear example of companies using our data against us to rip us off. The most famous recent exposé of this practice is Groundwork Collaborative’s report on how grocery delivery service Instacart charges users different prices depending on who they are.
Manitoba isn’t the only jurisdiction introducing bills targeting this practice, but I don’t believe anywhere in the US or Canada has actually managed to ban it yet. However, New York has made in mandatory for companies to disclose when they use personal data to set prices.
…Prediction markets incentivize bad behaviour · ↗ www.timesofisrael.com
The Times of Israel journalist Emanuel Fabian is claiming that Polymarket gamblers (sorry, “traders”) have threatened his life over a report he released about an Iranian missile attack on Israel on March 10. According to the rules, this bet resolves as true if Iran strikes Israel using a drone, a missile, or an air strike on this date. At issue here is this specific rule:
Missiles or drones that are intercepted and surface-to-air missile strikes will not be sufficient for a “Yes” resolution, regardless of whether they land on Israeli territory or cause damage.
On March 10, Fabian reported a single missile had hit an open area outside the Israeli city of Beit Shemesh; he included in the report a video of the strike. This would resolve the bet as “Yes”. Evidently, holders of “No” shares would very much like him to change his report to say that the missile was intercepted, which would resolve the bet as “No”, according referenced above. This bet has seen more than 23 million USD in trading volume.
If you look at the vitriol in the comments of the bet on Polymarket, I have no trouble believing people would send threats to a journalist demanding him to change his story, whether out of desperation to change their fortunes or just in an attempt to be edgy.
…Some insight into writing a book using Quarto · ↗ kieranhealy.org
Prof. Kieran Healy (Sociology, Yale University) shares some nice insight into the process of writing a book in Quarto using R in this post. The output screenshots he shares look beautiful, and the idea of deploying the same content as a clean PDF and a responsive website is awesome. A full draft of the book, Data Visualization: A Practical Introduction (Second Edition), is available as a website here.
I have grown increasingly tired of writing in any format other than a plain text file I can easily version control and move around, so the idea of writing a book in Quarto is appealing to me (as long as it has enough technical content to justify the format).
Using Claude Claude for cross-package statistical audits · ↗ causalinf.substack.com
Economist Scott Cunningham shared an important example of why we should always report the statistical package and version used in our analyses, as he used Claude Code to produce six versions of the exact same analysis using six different packages in R, Python, and Stata. In a difference-in-differences analysis of the mental health hospital closures on homicide using the standard Callaway and Sant’Anna estimator (for DiD with multiple time periods), he got very different results for some model specifications.
Since the specifications and the data were identical between packages, he discovered the divergences occurred due to how the packages handled problems with propensity score weights. Packages were not necessarily transparent about issues with these weights. If you were not running multiple analyses and comparing results across packages, or else carefully checking propensity score diagnostics, you might never have realized how precarious your results were.
Prof. Cunningham closes with the following advice:
The fifth point, and the broader point, is that this kind of cross-package, cross-language audit is exactly what Claude Code should be used for. Why? Because this is a task that is time-intensive, high-value, and brutally easy to get wrong. But just one mismatched diagnostic across languages invalidates the entire comparison, even something as simple as sample size values differing across specifications, would flag it. This is both easy and not easy — but it is not the work humans should be doing by hand given how easy it would be to even get that much wrong.
…
Getting citizenship just got a lot harder for those of Italian descent · ↗ www.cnn.com
Many people in the Americas would probably be surprised to learn that, in much of the rest of the world, being born in a country does not by itself make you a citizen. In most of the Americas, citizenship is automatically granted on the basis of jus soli (“right of soil”): birth on the territory. Elsewhere, citizenship is more often based on jus sanguinis (“right of blood”): descent. This is the case in most of the EU.
Citizenship in an EU country is considered unusually desirable because of the mobility rights and powerful passport it confers. However, the rules concerning exactly what kind of descent confers citizenship varies widely among member states. Italy used to be considered among the easiest, requiring only that an applicant prove they had an Italian ancestor alive after March 17, 1861, when the Kingdom of Italy was founded. That changed last year, when the country passed a new law significantly tightening the requirements for citizenship, which was recently upheld by the country’s Constitutional Court. The new law brings requirements more in line with norm among EU member states:
Now, only individuals with at least one parent or grandparent born in Italy will automatically qualify for citizenship by descent. The amended law does not affect the 60,000 applications currently pending review. Additionally, dual nationals risk losing their Italian citizenship if they “don’t engage” by paying taxes, voting or renewing their passports.
…
geoBoundaries: An open database of political administrative boundaries · ↗ www.geoboundaries.org
Today I discovered geoBoundaries, a CC BY 4.0-licensed database of political administrative boundaries covering the entire world. It is notable for its high level of detail, going from ADM0 (country), ADM1 (states/provinces), ADM2 (counties/departments or municipalities), to ADM3 (municipalities or sub-municipalities) for many countries. My go-to source for world map files is Natural Earth, which is limited to ADM0 and ADM1 but is in the public domain. Natural Earth also includes some physical geography like water and bathymetry, while geoBoundaries is focused solely on political administrative boundaries. Both datasets deal with disputed boundaries, which is an endless source of tension in the Natural Earth GitHub.
An R package for retrieving data from geoBoundaries, geobounds, was released in February. A similar package for Natural Earth, rnaturalearth, has long been maintained by rOpenSci.
Open banking comes to Canada · ↗ www.forbes.com
Canada’s banking sector is legendarily stable. However, this stability comes at the cost of innovation. Canada lags behind peers such as the EU, UK, US, and Australia in an area I care a lot about: open banking.
The premise of open banking is that consumers should be free to share their financial data with the third parties of their choosing, such as a budgeting app.. I have been following open banking in Canada for years now, ever since I started closing tracking my own finances. For a long time, I have been looking for a better way to export transactions than logging into my bank’s website and manually downloading a CSV file representing a certain time range.
Over the years, people have tried to solve this problem by writing third-party packages to retrieve data from specific banks. However, these packages were fragile and prone to breaking, and they usually relied on you providing your full account credentials, granting them to ability to impersonate a login to your account. Shockingly, this is actually the default security model for Canadian fintech companies: even a humble budget app must be given your username, password, and (implicitly) the ability to take any action on your behalf. Needless to say, this is at best a grey zone for liability, since you are willingly handing over the keys to the kingdom to a third party.
…The other half of the ATM–bank teller story · ↗ davidoks.blog
David Oks had a great post yesterday on the classic parable of how the adoption of ATMs did not lead to the predicted job losses among bank tellers. In fact, the opposite occurred: the number of bank tellers rose. I heard this story recounted several times in early discussions I had about the anticipated effect of AI on labour. I think I first heard it from Ryan Khurana. More recently it has been trotted out by US Vice President JD Vance.
The problem with this story is that the key statistic quoted alongside it, namely that there are more bank tellers than ever before, is no longer true. The famous graph supporting this assertion stops in 2010, and with good reason: the number of bank tellers has sharply fallen since then.
I think I had come across this fact before, this second half of the famous ATM–bank teller story, but it wasn’t until I read David Oks’s post that I understood the reason behind it. Quite simply, mobile banking ate physical banks. The ATM didn’t reduce the demand for bank tellers because it simply changed the kind of labour they did inside the bank. The iPhone made it so we didn’t need to go to the bank at all. It changed the paradigm. Explained this way, it seems obvious. Many new banks (including my own) do not have physical locations and never did.
…What will the paper of the future look like? · ↗ i4replication.org
I am sharing today a short blog post by the Institute for Replication: “What will the paper of the future look like?”
In short: research looking more like software development (as presaged by Prof. Richard McElreath, author of the excellent Statistical Rethinking), with the ability to reuse common material, formalize results, and remix analyses built into the pipeline.
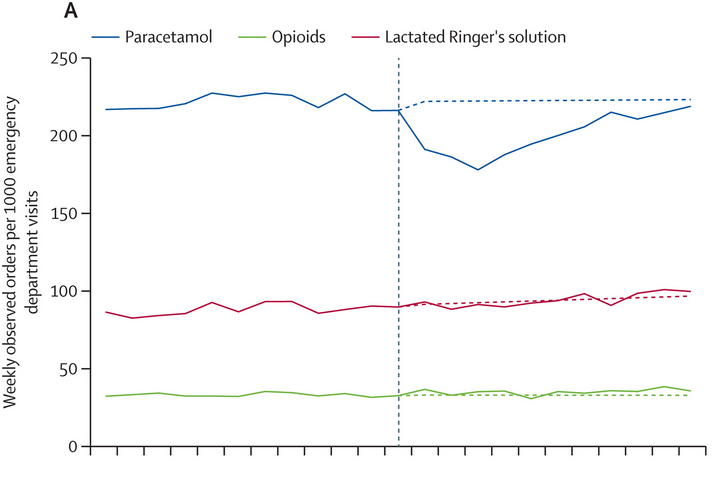
Changes in acetaminophen use after the White House Tylenol briefing · ↗ www.thelancet.com
Back in September 2025, US President Donald Trump and Health and Human Services Secretary Robert F. Kennedy, Jr. held a White House briefing linking Tylenol (acetaminophen, or paracetamol to Europeans) use in pregnancy to autism. A new study in The Lancet looks at what happened to acetaminophen prescriptions during emergency room encounters for pregnant females aged 15–44. They used data from a large database covering over 1,633 hospitals and 37,000 clinics.
Here is panel A from the figure in the study, with the vertical dashed line marking the date of the White House briefing (September 22, 2025) and the other dashed lined showing the expected prescribing rates (compared to the observed ones).
Canada exports a lot of coal, but not for power generation · ↗ thehub.ca
This provocatively titled piece in the The Hub (“Why the world needs even more Canadian coal”) made me realize I know very little about one of Canada’s most important exports: coal.
Coal is often villainized because it is incredibly dirty way of generating power. I vaguely recall an article from maybe 20 years ago claiming something along the lines of “if everyone in Canada replaced their incandescent bulbs with energy-efficient ones, the greenhouse gas savings would be cancelled out by a single coal plant that China is building every [some shockingly short amount of time]”. Although, China’s dependence on coal for power has been falling for the past two decades.
It turns out LLM-assisted search is fantastic for finding these half-remembered quotes. Here is the exact article and quote I was remembering, from a 2008 Macleans magazine article (I was pretty close):
Even if every household in the U.S. screwed in an energy-efficient light bulb today, the savings in greenhouse gas emissions would be wiped out by fewer than two medium-sized coal plants - the kind of plant that is being built in China at a rate of one a week.
But coal is also used to make most of the world’s steel (“metallurgical coal”), and this is the kind of coal that Canada (or specifically, British Columbia) overwhelmingly exports. The article goes on to claim that Canada’s production of metallurgical coal is among the cleanest (by greenhouse gas emissions) in the world.
…Open By Default: A database of access to information requests to the Canadian government · ↗ theijf.org
In Canada, any person or corporation in the country can make a request for general records to any agency of the federal government through the Access to Information Act (the equivalent in the United States is the Freedom of Information Act). The government provides a searchable database of completed requests, but includes only a summary of the request and the number of pages of responsive material. The actual documents turned over are not included. However, completed request packages may be informally re-requested, and should you do so, someone from the relevant agency will (usually) send them to you eventually.
This re-request process has its limits. It can takes weeks or months for the documents to be sent, and the database itself only goes back to January 2020 (they used to delete records older than two years, but stopped doing this some time after 2020). Occasionally, they will never send the documents at all, and all you can do is either re-request them again or open a formal access to information request (which will cost you $5).
Making it easier to access completed access to information requests is why the Investigative Journalism Foundation built Open By Default, “the biggest database of internal government documents never before made publicly accessible”. It includes documents from completed access to information requests obtained using both automated (presumably the re-request form) and manual processes (donations from trusted partners, particularly of documents from before the online re-request form was available). The files are cleaned and OCRed into one beautiful, searchable database.
…The surprising whimsy of the Time Zone Database · ↗ github.com
Time zones are hard. As a well-known Computerphile video so eloquently puts it:
What you learn after dealing with time zones, is that what you do is you put away your code, you don’t try and write anything to deal with this. You look at the people who have been there before you. You look at the first people, the people who have dealt with this before, the people who have built the spaghetti code, and you thank them very much for making it open source, and you give them credit, and you take what they have made and you put it in your program, and you never ever look at it again. Because that way lies madness.
The Canadian province of British Columbia recently decided to switch to permanent daylight time. I wanted to see if this update made it to the IANA Time Zone Database yet. Luckily, we can now view updates to this database as commits on GitHub. And there it was in the news file!

I’ve perused the tz repository before, and I always learn something interesting. For example, during WWII Britain adopted double summer time, adding two hours to the clock in the summer and one hour in the winter. The bulk of the comments in the database are dedicated to documenting this extensive history of time zone changes across the world.
Editors hate this one weird trick
Given my recent posts on AI in academic publishing, I just wanted to share this joke from Prof. Arthur Spirling on Twitter:
Actually you cant run my paper through Claude to desk reject it because Claude is a regular coauthor of mine. Conflict of interest. Checkmate, editors
Homeownership rate doesn't mean what you think it does · ↗ x.com
This thread from demographer Lyman Stone on the definition of the US homeownership rate has stuck in my head for a couple of years now. Reading it produced a pretty profound “oh” for why this particular metric didn’t line up with my perception of the issue.
To put it simply, the definition of the homeownership rate is:
Take the number of households where the home is owned by the household head, divide by the total number of households.
The homeownership rate is based on households, not individuals. If an adult child lives with their parents (and their parents own their own home), they are counted as “homeowners” for the purpose of the homeownership rate. If more and more people in their 20s and their 30s move in with their parents (or never move out in the first place) rather than renting an apartment, this has the effect of increasing the homeownership rate, because you have reduced the denominator (number of households) without changing the numerator (number of owner-occupied households).
Canada uses the same definition:
The homeownership rate refers to the proportion of all households that are owner occupied.
The productivity shock coming to academic publishing · ↗ causalinf.substack.com
Today, I wanted to share this piece from economist Scott Cunningham (Baylor University), who wrote about how AI is widening the gap between research and publishing. Or, in economics terms (emphasis mine):
But what happens when the same productivity shock hits a system where the bottleneck was never really production in the first place, but rather was a hierarchical journal structure that depended immensely on editor time, skill, discretion and voluntary workers with the same talents called referees for screening quality deemed sufficient for publication?
The post mentions the Autonomous Policy Evaluation project—the end-to-end AI paper pipeline I wrote about a few weeks ago—and discusses the likely consequences of this flood of AI-generated papers. Assuming the number of publication slots in reputable journals is relatively fixed, AI-generated papers should add a very large amount of mass to the left side of the paper quality distribution. Acceptance rates will plummet and journals may rely on other signals of quality (name recognition, pedigree, institution) to thin the herd before actually reviewing content. As always, the rich get richer!
But this is imperfect, not to mention unfair, and so desk rejection gets noisier: good papers get killed by tired editors and marginally lower quality papers slip through to referees. It’s a cascading failure: volume breaks editors, broken editing wastes referees, wasted referees slow science.
…
Testing ZeroClaw, Part 1: Setup
As mentioned last week, I’ve been meaning to test out a personal agent from the Claw-like ecosystem. I settled on testing out Zeroclaw, a popular and lightweight OpenClaw alternative that should run well on my Raspberry Pi 4 4GB.
I wanted to harden my setup as much as possible and opted to running everything in Docker. I started with the official Docker compose file and added my OpenRouter key. I brought up the pre-built container image and tried sending the basic “Hello” message to the agent using the CLI. However, I got error because the automatically generated config file defaulted to a version of Claude Sonnet 4 that wasn’t available on OpenRouter. I switched to claude-sonnet-4.6 and then gpt-oss-20b (for much cheaper testing).
The Zeroclaw web gateway was a bit of a mess. Of the features I tried, only memory management and the basic status dashboard worked. Trying to talk to the agent through the web interface would give me a black screen (here’s someone complaining about the same error). I’m still being charged for the tokens, though! The cost tracker always displayed zero, even as I sent CLI and Telegram messages (more on that soon). The configuration editor gave me an error and so did the diagnostics tool.
The project docs/wiki were helpful for figuring things out, but development is running so far ahead of releases that a bunch of the features referred to aren’t available in the current stable version (v0.1.7, from last week). This includes getting and setting specific config options from the CLI and resetting the gateway pairing token. To use these features, you have to compile yourself.
…Some examples of just-build-things-ism
The best mantra to come out of the AI era is: “You can just build things”. (So good OpenAI ripped it off for their Super Bowl ad.)
I’ve been pretty inspired to see how many people are now building all kinds of incredible tools thanks to advances in AI coding agents, even if they have no previous background in coding (see my post on Havelack.AI from a few days ago).
Here are a few more examples I’ve been following:
- Canadian journalist Alex Panetta writes about his AI-augmented workflow at A.I. For You. I first came across his work with his debut article “I killed my doomscrolling habit with AI. You can too”. In it, he explains how to vibe code an automated, personalized daily news digest. I’ve tried to build something for myself but I haven’t gotten it quite right yet. A great follow for big news consumers.
- Economics professor Scott Cunningham, author of the great textbook Causal Inference: The Mixtape, has a presentation explaining how to encourage AI adoption among academic faculty. This starts with faculty experiencing a killer use case for AI, which he suggests is building slide decks. He shares his tools/agent skills for this use case and more on GitHub.
- Another economist, Chris Blattman, built a website to share the productivity tools he developed with Claude Code. He provides a tutorial and code on Claude Blattman.
And of course, Simon Willison has been building and sharing tools habitually for years now.
Will you peruse this post? · ↗ www.merriam-webster.com
I learned a new word today: contronym. It means a word whose definitions contradict each other. The example, thanks to a random Silicon Valley clip, is “peruse”. I’ve always used this word synonymously with “skim”, but Merriam-Webster presents two contradictory definitions:
- to examine or consider with attention and in detail
- to look over or through in a casual or cursory manner
I think I was vaguely aware of this definitional confusion, but only today did I learn that there was a term for this category of words.
Another one that annoys me is “sanction”…to sanction a behaviour can either mean to endorse it or to punish it…not helpful!