transcribe.cpp: Local transcription library · ↗ workshop.cjpais.com
CJ Pais has released transcribe.cpp, a cross-platform library that aims to support all of the major transcription models. It is designed as a mostly drop-in replacement for the model-specific whisper.cpp. The project serves as the new back end to his earlier Handy speech-to-text app.
This all seems promising. Transcription is widely useful and already practical to run locally on ordinary hardware, even without a GPU. As such, it should be at the frontier of the shift to local-first AI.
Hat tip to sebjones on Hacker News.
What happens inside an LLM? · ↗ www.0xkato.xyz
This is a nice, in-depth explanation of how LLMs work by security researcher 0xkato, especially if you don’t want to trip over matrix multiplication. (Not that there’s anything wrong with linear algebra, it can actually be quite psychologically satisfying.) But the article is a good way to get a handle on the terminology underlying large language models without getting hung up on the math.
The telltale cliff
Suspicious discontinuities in data
Dan Luu has a wide-ranging post documenting suspicious discontinuities in data, such as marathon runners pushing themselves to achieve round number finishing times, especially half-hours; published p-values clustering just below the magic threshold of 0.05; and Russian voters apparently favouring turnout percentages that are multiples of five.
I wrote a much narrower post on the same subject a few years ago. But mine had gigantic underwater sea walls!
Hat tip to tosh on Hacker News.
tongfen: The least common geography
https://mountainmath.github.io/tongfen/articles/tongfen.html
TongFen is a Chinese term referring to the conversion of two fractions to the least common denominator. It is also the name of an R package, tongfen, created by Jens von Bergmann to reconcile shifting geographic boundaries across years, primarily for census data.
This is a common problem. You want to compare census data, voting patterns, or some other geographic measure across time, but discover that the subunits do not quite line up. Maybe some of them merged, or they split, or someone simply redrew the boundaries a little nicer. The package helps you work out what happened and resolve the resulting conflicts. It makes a frustrating and manual process a little smoother.
Einstein and the magician · ↗ medium.com
The first of Chuck Klosterman’s 23 questions
A friend told me the other day that I might enjoy the writer Chuck Klosterman. He pointed me toward his famous “23 Questions I Ask Everybody I Meet In Order To Decide If I Can Really Love Them”, a set of hypotheticals meant to be argued over at a bar.
I haven’t read the whole list yet, but I did get a chance to argue a little over the first question:
Let us assume you met a rudimentary magician. Let us assume he can do five simple tricks he can pull a rabbit out of his hat, he can make a coin disappear, he can turn the ace of spades into the Joker card, and two others in a similar vein. These are his only tricks and he can’t learn any more; he can only do these five. HOWEVER, it turns out he’s doing these five tricks with real magic. It’s not an illusion; he can actually conjure the bunny out of the aether and he can move the coin through space. He’s legitimately magical, but extremely limited in scope and influence. Would this person be more impressive than Albert Einstein?
So what is more impressive, to uncover the laws of physics or to break them in relatively trivial ways?
My mind jumped to a related distinction. Presumably, the magician’s abilities are innate, whereas Einstein’s discoveries were the result of hard-fought intellectual effort. This, in turn, reminded me of Aristotle’s distinction between virtue and self-control. The virtuous person does the right thing easily because his desires are properly ordered. The self-controlled person must struggle against his desires but succeeds anyway. Aristotle considers the first person more fully virtuous, although the second may strike us as more impressive.
…Adam’s rib · ↗ stephenskolnick.substack.com
Sometimes you read a piece of writing that grabs you by the shoulders and shakes you. This article by Stephen Skolnick, which I found through Freddie deBoer’s monthly subscriber writing roundup, is one such piece. Its subject is the meaning of “rib” in the biblical story of Eve’s creation from Adam.
I won’t spoil it, but when I reached the turn—“And the moment I saw those words, three memories collided in my mind”—I felt as though I were falling and the ground had suddenly rushed up to meet me. Given the nature of the hypothesis, only male readers are likely to share this experience.
I looked up the scholarship on this unusual interpretation of Adam’s rib, and it seems to be pretty niche. That makes the essay more interesting to me, not less. The collision of memory makes the hypothesis feel unearthed rather than articulated. The tender speculation that follows adds emotional weight, if not scholarly support. By the end, I found the idea hard to dismiss.
Can Quebec and Alberta untangle their spaghetti code together? · ↗ www.cbc.ca
The Canadian provinces of Quebec and Alberta have signed a five-year agreement to share AI knowledge and tools. The agreement includes no financial commitment. This announcement follows another recent press release from Anthropic about the Government of Alberta’s use of “Claude to find and fix cybersecurity vulnerabilities across government systems”. Canadian readers will know that Quebec and Alberta are not natural bedfellows, which makes the agreement more interesting.
Every Canadian province has struggled in one way or another with IT and digital infrastructure. Quebec’s latest scandal is SAAQclic, a modernization project for the provincial automobile insurance system that is expected to come in more than half a billion dollars over budget.
I will choose to be optimistic. AI coding harnesses are powerful, and Claude Code might be just the tool for cutting through decades of unmaintainable spaghetti code. Of course, we might simply end up with an even bigger bowl of spaghetti.
Time will tell. But since every province faces versions of the same problems, I am glad they are finally agreeing to copy each other’s homework.
Prediction markets: You’re always betting against the house
Here’s a round-up of a few recent prediction market stories. Try to spot the common theme!
- Google employee charged with $1M Polymarket insider trading bet on search term: A Google software engineer was charged with using non-public “Year in Search” data (including that singer d4vd was the most searched person of 2025) to make more than $1.2 million.
- DOJ investigating ex-US lawmaker Santos for insider trading on Kalshi, source says: The former congressman allegedly bet that he would not attend the State of the Union after publicly suggesting that he would.
- White House teleprompter operator made more than $100K betting on Trump’s speeches: Sources: A technical assistant who has operated Trump’s teleprompter since 2016 allegedly bet on the contents of the president’s remarks (while regularly receiving last-minute edits from Trump himself).
In the words of Polymarket CEO Shayne Coplan: “What’s cool about Polymarket is that it creates this financial incentive for people to go and divulge the information to the market.”
Housing starts start too late · ↗ www.missingmiddleinitiative.ca
The problem with how Canada measures housing starts
Professor Mike Moffatt of the Missing Middle Initiative explains in this article why Canadian data on housing starts are problematic. In short:
- The Canadian definition of a housing start is out of step with those used in peer countries. For a project to be counted as a housing “start”, its foundation must be completed and at grade. For some projects, this can occur a year or more after construction begins.
- Housing starts therefore generally reflect the health of the housing market two or more years earlier, when the relevant business decisions were made. This makes Canadian housing starts a poor real-time indicator.
- Governments in other countries track pre-construction or new housing sales and excavations, both of which occur much closer to the business decisions that lead to new housing than the point captured by Canada’s current definition of a housing start. These would be better real-time indicators of the health of the housing market.
Where I learned about lockdowns
I read a lot of Tom Clancy novels as a teenager. Something about the extremely detailed writing and overly elaborate plotting scratched an itch. I was also a big fan of the Splinter Cell games.
The 1996 novel Executive Orders—the one where Clancy’s self-insert hero Jack Ryan becomes president—has always stuck with me. Like all Clancy doorstoppers (this one is nearly half a million words), it has many subplots. The most memorable one involves terrorists backed by the Ayatollah of Iran starting an epidemic in the United States using aerosolized Ebola. The attack has two purposes: to kill Americans and to paralyze the country so it cannot respond to Iran’s invasion of its neighbours.
What makes the subplot memorable is that the biological attack just…doesn’t work that well. It kills thousands instead of millions. It is fairly successful at preventing the normal deployment of American military forces to the Middle East, but luckily for America’s allies, the available units are sufficiently badass to hold off the Iranian invasion anyway.
The epidemic fails for two reasons. First, although the terrorists successfully aerosolize the virus in shaving-cream canisters and release it at roughly twenty conventions and trade shows across the country, Ebola simply does not transmit very well under ordinary circumstances. Most of the secondary infections come from close personal contact.
…LinkedIn case
I have been spending more time on LinkedIn recently.
Every post is either AI-generated or written in the style AI was trained on.
The sentences are short.
The clauses are never subordinate.
Every sentence gets promoted to a paragraph.
Each of life’s moments becomes a lesson in leadership.
I call this LinkedIn case.
Which date counts?
Two types of ghost curves
I recently read this post from Paul Goldsmith-Pinkham on why the number of economics preprints submitted to arXiv and similar preprint servers is not exploding quite as dramatically as some charts suggest.
Basically, if you plot papers by the date they were last updated, you create a large upward bias in the most recent months. Old papers revised today are counted alongside papers first submitted today. The chart will therefore show a sudden explosion near the present whenever you produce it.
If you plot the papers by their first submission date instead, and recent growth looks much closer to the historical trend. Goldsmith-Pinkham still found that the number of new papers was growing faster across most of the fields and preprint servers he examined, but the apparent vertical takeoff was partly an artifact of the date variable.
This all reminded me of one of my COVID-19 pandemic hobbyhorses, which annoyed me enough that I wrote a paper about it: which date variable to use when plotting an epidemic curve.
Epidemic curves are commonly plotted by either date of symptom onset or date of public reporting. Symptom onset is closer to the actual infection, so it intuitively seems to offer a more “real-time” view of the epidemic. But recent onset dates are necessarily incomplete. When someone develops symptoms, it takes time for them to seek testing, book the test, receive a result, and have that result communicated to public health authorities. A case reported today may therefore have developed symptoms days or even weeks ago. New cases are continually added to the older part of the symptom-onset curve.
…The best feature in sports sims
Export CSV
The other day I was curious what kind of hockey games were on Steam and came across this review of Franchise Hockey Manager 12 by someone who had built an AI assistant general manager for his OHL team.
The game can export an entire save as CSV: roughly two million rows across 48 tables, including rosters, statistics, player ratings, and scouting grades. The player wrote a Python script to load each export into SQLite, preserving snapshots from different in-game dates, then put a local MCP server on top of it. With this, his AI assistant GM can query the actual save, track changes in prospect ratings, build draft boards, grade draft classes, write monthly reports, and score the roster against a custom 100-point rebuilding rubric. It even noticed that a goalie prospect had lost half a star of potential because the coach was not starting him.
I guarantee this guy is having more fun playing the game than anyone else. Players of simulation games are known to be obsessive, but this guy built a full data warehouse for his virtual junior hockey league that is probably more sophisticated than the data warehouses at some actual corporations.
The interesting part is that none of it starts with AI. It starts with an “Export CSV” button. All of this is possible because the studio made the underlying game data available in a legible format; one obsessive player did the rest. Save files are often just compressed JSON and can be extracted and parsed with enough effort, but that is not the same as providing a supported export of nearly everything the game knows. As the reviewer put it: “Franchise Hockey Manager 12 quietly has one of the best features in sports sims: Export CSV”.
…My most cancellable academic take
Honorary degrees are bad
My most cancellable academic take is that honorary degrees are bad. I have three reasons.
First, handing out honorary degrees creates an unforced reputational attachment to figures who may later become embarassing. Any award can age badly, but an honorary degree trades on the university’s authority to certify education. For example, the School of the Art Institute of Chicago had to revoke Kanye West’s honorary degree when he started throwing up metaphorical Hitler salutes (later literal ones). Universities could avoid this humiliation ritual if they stopped bribing celebrity speakers with fake credentials.
Second, an honorary doctorate cheapens the value of an actual doctorate. A doctorate is mainly a certificate of endurance. As the old joke goes, “All dissertations are bad but some are finished.” An honorary doctorate is just an honour—it goes under the awards section of LinkedIn, not education.
Finally, honorary doctorates create the rare but entirely avoidable temptation for already successful people to call themselves “Doctor”. At least in the US and Canada, it is already a borderline faux pas for legitimate PhD holders to use the title outside of rarefied academic settings. For honorary degree holders, it is just embarrassing.
What happens when the guy with 1% of the votes votes to give himself all the money? · ↗ www.coindesk.com
In crypto, he gets all the money
DAOs (decentralized autonomous organizations) are organizations governed by votes on the blockchain, typically with votes proportional to tokens held. Of course, this being crypto, any supposed purpose is usually overshadowed by speculation on the price of the underlying coin.
DAOs have a storied history of failure. The original DAO caused the second-largest blockchain to split in two over whether to undermine the fundamental promise of crypto to bail out rich token holders (the yes side won). Another DAO raised money to buy a copy of the US Constitution and failed, only to discover that issuing refunds is really expensive in crypto.
But today’s story is one of a DAO working exactly as intended.
BonkDAO governs BONK, yet another dog-themed meme coin. It controlled a treasury worth about $20 million USD. An anonymous wallet spent $4.4 million USD buying just over 1% of the total supply of BONK. This was somehow enough to meet the DAO’s quorum requirement all by itself.
The wallet proposed transferring the entire treasury to another address it controlled. Only seven wallets bothered to vote, and only two voted yes: the creator of the proposal and one other random wallet. But that was enough for the proposal to pass with 99.9% of the voting power. The transfer then executed automatically.
BonkDAO has called this an attack and contacted law enforcement, which feels a little unsporting. There was no hack and no code exploit. The so-called attacker bought the votes, proposed giving himself all the money, won, and collected.
…A picture worth nothing
What happens when images become free and ubiquitous?
Yesterday I used ChatGPT to generate a dumb parody logo for a post. I was never going to pay an artist to make it. Without AI, there simply would have been no image, no extra joke.
On the other hand, I feel a sort of visceral disgust when I see AI art in online ads or restaurant food pictures or business signs, at least when they use a generic slop style. When deployed thoughtlessly, the outputs tend to have a slightly sickly quality to them. There’s a really weird trend of faux-claymation YouTube ads right now; before that, it was weird, overwrought AI-generated songs over generic, sad-looking slop people.
I am not broadly anti-AI. There are corners of the internet that would dismiss me simply for acknowledging any use of AI in my work. But I also understand why artists are angry. When your livelihood depends on making images, a tool that can produce an unlimited number of them for almost no money is not an abstract philosophical problem.
At the same time, I find myself making a distinction between uses that replace paid work and uses where the realistic alternative was nothing. Like, do I think Freddie deBoer, hardly an AI booster, is committing a grave sin when he sometimes uses AI to make a jokey blog header? He said it works well with his spontaneous writing style, though he checks Getty Images first. For my old newsletter, I used to get header images mainly from free sites like Unsplash or Pexels. So while I was never going to pay anyone, I guess I could be denying an artist exposure or discovery if I turn to an AI-generated image.
…A Stake in the future
The casino is paying for the internet
![]()
Parody logo generated by ChatGPT.
Stake is everywhere online.
The logo for the online, crypto-based casino appears everywhere: on streams, sports highlights, clip-farm accounts, and the endless slurry of short-form video content. The videos often have nothing to do with gambling.
The online streaming platform Kick, where streamers go after being banished from the more “respectable” Twitch, is one of the most watched video platforms in the world. It was created to funnel viewers onto Stake’s online gambling site. Your teenage son’s favourite content creator is a man sitting in his bedroom losing thousands of dollars a day on the site (using the house’s money).
There are still small oases. YouTube banned the promotion of some gambling sites like Stake. But Stake is escaping into the real world too, sponsoring a Formula 1 team, a Premier League club, and esports teams. Its logo was plastered across the octagon at the UFC fight on the White House lawn.
The old promise of the internet was that creators would no longer need television networks, record labels, or publishers to reach an audience. Well, we got our wish. Gambling sites have swallowed the entire chain, from the people making the content, to the accounts sharing it, to the platforms hosting it.
…The planter is on fire
Friends don’t let friends butt out in organic material

I was walking through my neighbourhood yesterday when I noticed, out of the corner of my eye, burning plastic and cinders falling into the shrubs next to a house. I took a few more steps, my brain not quite processing what I had seen. Then I turned around for a better look.
A planter on the second-floor balcony of a duplex was on fire.
I tried pounding on the door to get the attention of anyone inside. Meanwhile, another neighbour called the fire department, as we were both concerned the shrubs underneath would catch. Thankfully, the occupant eventually woke up and flung the planter off the balcony, giving us a nice little shower of dirt.
The picture doesn’t really do it justice. It was burning quite dramatically at the beginning!
I’ve never come across anything quite like this. There were no obvious sources of ignition nearby, so the most likely explanation is that someone tried using the planter as an ashtray, not realizing that butting out in organic material (e.g., peat moss) after a prolonged heat wave may not be wise.
Another reason not to smoke!
Yes, I’m still mad about Time’s Person of the Year for 2006
That’s right, I’m mad at myself. I was Time’s Person of the Year, and so were you, assuming you were born before 2006. Yes, Time’s Person of the Year for 2006 was… “You”.
Time magazine is fond of these collective awards. Hardly a decade goes by without one or two. Some are more inspired than others, but to be quite honest, collective awards are weak and cowardly choices as a category.
I once considered studying under a professor who listed a Nobel Peace Prize on his CV. He wasn’t wrong: he was, in fact, part of the International Physicians for the Prevention of Nuclear War when they won the Nobel Peace Prize in 1985. But that doesn’t make these mushy selections any more satisfying.
The contemporaneous reaction to my (and your) selection as Time’s Person of the Year was…not positive.
What a cop-out! They couldn’t decide amongst all of the wack — jobs in the news today, so they gave up and chose YOU. What a joke. — Craig Chicago, IL
Many commenters pointed toward one of two alternative choices: US President George W. Bush (for the War in Iraq) or Iranian President Mahmoud Ahmadinejad (who was causing quite a stir at the time).
With the benefit of hindsight, Al Gore would have been the best choice. An Inconvenient Truth came out that year, and Gore won the Nobel Peace Prize the the following year. Nobody did more than Gore to make climate change a permanent fixture of Western politics.
…Here we are · ↗ gutenberg.ca
There’s a line in C.S. Lewis’s The Screwtape Letters that I keep coming back to:
For the Present is the point at which time touches eternity.
For Lewis, humans live in time but are destined to eternity. In the book, a senior demon advises his nephew on how to tempt a human soul. Screwtape says to draw us away from the present and toward the future, “the thing least like eternity”. Nearly all vices, he explains, are rooted there. Fear looks ahead, as does ambition. We can lose days fearing things that have not happened, or years waiting to become the person we thought we were meant to be.
Lewis does not dismiss planning, for planning tomorrow’s work is one of today’s duties. But we ought not to give our hearts to the future. Our treasure does not lie there.
Yotta is the 21st century in miniature
The whole world has become a casino
Yotta was everywhere on YouTube a few years ago, sponsoring an army of personal finance and general-interest creators. The idea was brilliant: use the psychology of gambling to trick people into saving money. For every $25 saved, players (sorry, depositors) would get one ticket to win the weekly jackpot of up to $10 million. Meanwhile, funds sat securely in an FDIC-insured savings account. All the fun of gambling except you can never lose.
Somewhere along the way, Yotta or one of its partners (Synapse and Evolve Bank & Trust) did an oopsy and lost track of somewhere between $60 and $90 million USD. In 2024, depositors found out about this and also that their funds weren’t FDIC insured after all. Many ordinary users lost basically everything.
Unlike the collapse of Silicon Valley Bank the year before, when the government stepped in to make wealthy depositors and venture-backed companies whole, nobody was coming to save them. These were ordinary people, after all.
Yotta still exists. It’s just a straight-up casino now.
The whole world has become a casino, as one of our era’s great cultural observers put it.
Beliefs are not choices
People talk about beliefs as if they are choices. But they aren’t, not really.
I could not simply decide to believe that The Beatles were the worst band of the 1960s. I could say it; I could act like I believed it; I could maybe even force myself to spend enough time around weirdos to start believing it.
But I cannot choose to believe it. Either I am convinced of something or I am not.
Am I a technocrat?
Not quite
I recently asked an LLM to infer my ideological leanings purely through my post history on this blog. It pegged me as, among other things, a technocrat.
Okay. I am all for science and expertise. I think public policy should be grounded in evidence. I want a competent administrative state. But I don’t think the label quite fits.
Getting a PhD made me more skeptical of scientific evidence, not less. The process of evidence generation is full of choices: how to frame the question, what to measure, who to cite, which limitations to admit, when to stop fighting reviewer two, and why anyone should care in the first place. Scientific results are rarely clean, at least not the kind that end up informing policy.
This is also why I am cranky about certain phrases. I prefer the term “evidence-informed” over “evidence-based”, because evidence can be an input into the decision-making process but cannot define the values that guide it.
The same goes for “follow the science”. This slogan annoyed me so much I even wrote a piece about it in The Hub a few years ago. The key passage:
In reality, “science” cannot dictate policy, because science cannot weigh the value of particular freedoms against specific risks, any more than it can tell you how to feel about a sunset. Policy is about making trade-offs, based on a set of values and goals, in the light of evidence.
…
Twitter discovers the Kelcey Rule
If you have a slop problem, start by not subsidizing it.
Twitter’s head of product recently had the following revelation about the platform’s revenue sharing program:
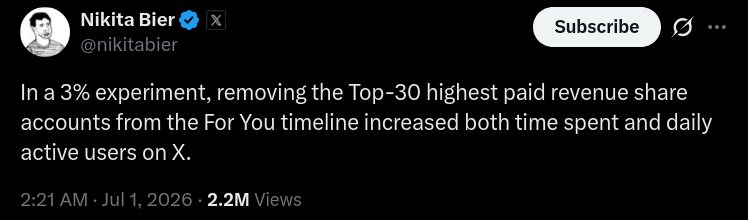
As predicted by everyone when Twitter announced their revenue-sharing program in 2023, paying people to ragebait your users is not a recipe for long-term success. Posters gotta be in it for the love of the game.
Basically, Twitter ran into the Kelcey Rule:
Before a government tries to solve a problem, it should first make sure it’s not already subsidizing the problem.
Substitute “platform” for “government” and there you go. If you have a slop problem, maybe stop paying people to make slop.
Thermal shock · ↗ www.noahpinion.blog
Europe’s fear of air conditioning is making heat waves deadlier
Europe just experienced a heat wave that literally cooked thousands of people to death. This annual tragedy has once again reignited the debate over air conditioning, the use of which remains shockingly rare in Europe. It is also a good excuse to re-up Noah Smith’s excellent piece on Europe’s crusade against the life-enabling technology.
The European objection to AC seems to be more cultural than anything. Yes, energy is more expensive in Europe than in the US or Canada, but for most households it would not be devastatingly expensive to run AC during a heat wave. That is especially true in hospitals, nursing homes, and long-term care facilities, where many preventable heat-related deaths occur.
Europeans have adopted a variety of superstitions around AC, including the French fear of a dangerous, even life-threatening condition called “thermal shock”, supposedly caused by moving from the hot outdoors into an air-conditioned room. Of course, this AC-related malady exists nowhere where AC use is common.
The belief that AC is harmful seems to be reinforced by European ideas around climate change and degrowth: it is unfair, even selfish, to use energy to deal with the heat, since rising temperatures are a consequence of climate change. This frame has never made sense to me, as I have long been convinced of technological and economic solutions to climate change. There’s a reason Texas is the US state with the highest utility-scale solar energy production: because it works. It is not because Texas suddenly became woke on climate change. Energy is the currency of civilization, and we should aim to produce as much of it as possible, as cheaply and cleanly as possible.
China as Evil Empire · ↗ www.richardhanania.com
The danger of “China will do it anyway”
Just before the pandemic started, I attended a talk on the ethics of genome editing using CRISPR. At the time, the main question on my mind was: What about China? What’s stopping them from using CRISPR to create an army of genetically modified super soldiers and taking over the world? And how should that threat change what we in the West were willing to do?
China was a convenient foil: infinitely ambitious, maximally ruthless, totally amoral. But now I am not so sure. This Richard Hanania post from 2024 pretty directly confronted the fears I had had a few years earlier:
Supporters of genetic engineering and embryo selection have sometimes argued that China is soon going to be creating super babies and so will eventually take over the world. Supposedly, it is our Christian morality and woke ethics that prevent us from realizing all the benefits of such practices, but a smart and pragmatic people like the Chinese can’t be expected to make the same mistake.
He goes on to point out that China is more restrictive than the US on biotech policy. Research connecting genetics to IQ is restricted. The first Chinese scientist to use CRISPR to create a genetically edited baby was thrown in prison, while his foreign collaborators went unpunished. Surrogacy is de facto illegal. The United States, and even Europe, are generally more permissive on genetic technologies than China. The fears about Chinese super soldiers have not come to pass.
…The literary bots are winning · ↗ unherd.com
Looks like that probably AI-generated story that won the Caribbean category of the Commonwealth Short Story Prize last month has won the overall prize, too.
Writer Vincenzo Barney predicted as much in his piece for Unherd shortly after the original controversy around the Caribbean category winner:
And if all of these finalists are real, and their work is their own, their writing operates by the same rules, and is still trash. Of the five finalists — one of whom is the verifiably real Lisa-Anne Julien, who has been published since 2021 and appears animated and otherwise alert and not-computer-generated in videos — the overall winner will be announced on June 30. For my money, I like Nazir’s work the best.
If you’ve ever tried using AI for fiction, you’ll know that it produces text that is often overwritten, with metaphors that sound deep but don’t actually mean anything. Several of the winning story’s passages in the quoted article have this unmistakable shape.
Barney comes to the same diagnosis for the degradation of writing as I did for the degradation of Internet culture: optimization for algorithms.
The writer was not hooking a reader anymore with an anecdotal lede, but hooking Google’s algorithm, which prioritizes algorithmic styles of writing, styles of writing that a computer can understand and parse. We have been reading and writing in this medium for three decades, watching the birth of the one-sentence opening paragraph — a contradiction in terms — in journalism, and the extinction of voice and style across all genres.
…
Golden egg machine broke
Another reminder that rich people are people

Masayoshi Son, the founder and CEO of SoftBank, the Japanese investment giant, dropped this profoundly weird slide deck a few days ago for his company’s 46th Annual General Meeting of Shareholders. The goose slides (and there are a lot of them!) start on slide 44. The guy has apparently been obsessed with golden goose metaphors for years.
But the whole slide deck is very weird.
The more people you meet, the more obvious it becomes that people are people. It does not matter if someone is rich, famous, successful, or brilliant. For the most part, you can just talk to them. You can just say things. There are exceptions, I’m sure. But people are weird, which means rich people are weird too.
Anyway, this slide deck is very weird.
Hat tip to David Gerard of Pivot to AI.
The (only) problem with soccer
Diving
Soccer (sorry, fútbol) is the only universal sport. So, like everyone else on earth, I am following this year’s World Cup, even if I only plan to watch a handful of games.
Soccer is a great sport. It can be played anywhere and by anyone. It is also a very athletic sport, and that makes it fun to watch, even if too many games end 0–0.
Soccer has just one problem: diving.
There is no other sport where faking injury is so central to winning a match. Every sport has gamesmanship, of course. But diving matters so much in soccer because of the game’s particular rules. Penalty kicks and free kicks are much more likely to produce goals than ordinary play. Getting those calls is often the difference between victory and defeat.
Diving is embarrassing. And soccer fans get embarrassed when you point it out. When it’s your guy going for the Oscar, your side is outraged by the accusation. When it’s the other guy, your side is outraged by the act. This awkward self-deception happens several times each match.
Whenever I see a dive, I wonder whether it is purely instinctual or something teams practice together. And why not? Diving is a skill like any other.
Soccer does not have a diving problem because soccer players are uniquely shameless. It has a diving problem because the rewards are enormous, the punishment is rare, and billions of people have agreed to be complicit in the ruse.
Hedge knights · ↗ arxiv.org
How AI flattens public debate
Kim, Chang, Pham & Iyyer have a new paper on what they call argument collapse: the tendency of LLMs to produce arguments that converge on the same small set of perfectly reasonable, perfectly plausible, perfectly hedged points.
This is not surprising, of course. Humans actually believe shit, often to the point of unreason. For us, disagreements have stakes. We want the world to be one way and not another.
Maybe the future of public debate is an army of hedge knights, bravely sallying forth to defend the safest possible version of the argument.
As an aside, I was reminded of a recent column in El Espectador by Felipe Zuleta Lleras, or rather by Felipe Zuleta Lleras “and Gemini AI”. Zuleta says he posed a question to Gemini, agreed completely with the answer, and signed the result. The resulting electoral endorsement is not particularly hedged (quite the opposite, really). But still: if being a columnist means broadcasting your thoughts to others, what is the point of outsourcing the thought? The transparency is good, I guess. But whence cometh the columnist?
Hat tip to Yekyung Kim (the lead author) on Twitter.