Twitter discovers the Kelcey Rule
If you have a slop problem, start by not subsidizing it.
Twitter’s head of product recently had the following revelation about the platform’s revenue sharing program:
As predicted by everyone when Twitter announced their revenue-sharing program in 2023, paying people to ragebait your users is not a recipe for long-term success. Posters gotta be in it for the love of the game.
Basically, Twitter ran into the Kelcey Rule:
Before a government tries to solve a problem, it should first make sure it’s not already subsidizing the problem.
Substitute “platform” for “government” and there you go. If you have a slop problem, maybe stop paying people to make slop.
Thermal shock · ↗ www.noahpinion.blog
Europe’s fear of air conditioning is making heat waves deadlier
Europe just experienced a heat wave that literally cooked thousands of people to death. This annual tragedy has once again reignited the debate over air conditioning, the use of which remains shockingly rare in Europe. It is also a good excuse to re-up Noah Smith’s excellent piece on Europe’s crusade against the life-enabling technology.
The European objection to AC seems to be more cultural than anything. Yes, energy is more expensive in Europe than in the US or Canada, but for most households it would not be devastatingly expensive to run AC during a heat wave. That is especially true in hospitals, nursing homes, and long-term care facilities, where many preventable heat-related deaths occur.
Europeans have adopted a variety of superstitions around AC, including the French fear of a dangerous, even life-threatening condition called “thermal shock”, supposedly caused by moving from the hot outdoors into an air-conditioned room. Of course, this AC-related malady exists nowhere where AC use is common.
The belief that AC is harmful seems to be reinforced by European ideas around climate change and degrowth: it is unfair, even selfish, to use energy to deal with the heat, since rising temperatures are a consequence of climate change. This frame has never made sense to me, as I have long been convinced of technological and economic solutions to climate change. There’s a reason Texas is the US state with the highest utility-scale solar energy production: because it works. It is not because Texas suddenly became woke on climate change. Energy is the currency of civilization, and we should aim to produce as much of it as possible, as cheaply and cleanly as possible.
China as Evil Empire · ↗ www.richardhanania.com
The danger of “China will do it anyway”
Just before the pandemic started, I attended a talk on the ethics of genome editing using CRISPR. At the time, the main question on my mind was: What about China? What’s stopping them from using CRISPR to create an army of genetically modified super soldiers and taking over the world? And how should that threat change what we in the West were willing to do?
China was a convenient foil: infinitely ambitious, maximally ruthless, totally amoral. But now I am not so sure. This Richard Hanania post from 2024 pretty directly confronted the fears I had had a few years earlier:
Supporters of genetic engineering and embryo selection have sometimes argued that China is soon going to be creating super babies and so will eventually take over the world. Supposedly, it is our Christian morality and woke ethics that prevent us from realizing all the benefits of such practices, but a smart and pragmatic people like the Chinese can’t be expected to make the same mistake.
He goes on to point out that China is more restrictive than the US on biotech policy. Research connecting genetics to IQ is restricted. The first Chinese scientist to use CRISPR to create a genetically edited baby was thrown in prison, while his foreign collaborators went unpunished. Surrogacy is de facto illegal. The United States, and even Europe, are generally more permissive on genetic technologies than China. The fears about Chinese super soldiers have not come to pass.
…The literary bots are winning · ↗ unherd.com
Looks like that probably AI-generated story that won the Caribbean category of the Commonwealth Short Story Prize last month has won the overall prize, too.
Writer Vincenzo Barney predicted as much in his piece for Unherd shortly after the original controversy around the Caribbean category winner:
And if all of these finalists are real, and their work is their own, their writing operates by the same rules, and is still trash. Of the five finalists — one of whom is the verifiably real Lisa-Anne Julien, who has been published since 2021 and appears animated and otherwise alert and not-computer-generated in videos — the overall winner will be announced on June 30. For my money, I like Nazir’s work the best.
If you’ve ever tried using AI for fiction, you’ll know that it produces text that is often overwritten, with metaphors that sound deep but don’t actually mean anything. Several of the winning story’s passages in the quoted article have this unmistakable shape.
Barney comes to the same diagnosis for the degradation of writing as I did for the degradation of Internet culture: optimization for algorithms.
The writer was not hooking a reader anymore with an anecdotal lede, but hooking Google’s algorithm, which prioritizes algorithmic styles of writing, styles of writing that a computer can understand and parse. We have been reading and writing in this medium for three decades, watching the birth of the one-sentence opening paragraph — a contradiction in terms — in journalism, and the extinction of voice and style across all genres.
…
Golden egg machine broke
Another reminder that rich people are people

Masayoshi Son, the founder and CEO of SoftBank, the Japanese investment giant, dropped this profoundly weird slide deck a few days ago for his company’s 46th Annual General Meeting of Shareholders. The goose slides (and there are a lot of them!) start on slide 44. The guy has apparently been obsessed with golden goose metaphors for years.
But the whole slide deck is very weird.
The more people you meet, the more obvious it becomes that people are people. It does not matter if someone is rich, famous, successful, or brilliant. For the most part, you can just talk to them. You can just say things. There are exceptions, I’m sure. But people are weird, which means rich people are weird too.
Anyway, this slide deck is very weird.
Hat tip to David Gerard of Pivot to AI.
The (only) problem with soccer
Diving
Soccer (sorry, fútbol) is the only universal sport. So, like everyone else on earth, I am following this year’s World Cup, even if I only plan to watch a handful of games.
Soccer is a great sport. It can be played anywhere and by anyone. It is also a very athletic sport, and that makes it fun to watch, even if too many games end 0–0.
Soccer has just one problem: diving.
There is no other sport where faking injury is so central to winning a match. Every sport has gamesmanship, of course. But diving matters so much in soccer because of the game’s particular rules. Penalty kicks and free kicks are much more likely to produce goals than ordinary play. Getting those calls is often the difference between victory and defeat.
Diving is embarrassing. And soccer fans get embarrassed when you point it out. When it’s your guy going for the Oscar, your side is outraged by the accusation. When it’s the other guy, your side is outraged by the act. This awkward self-deception happens several times each match.
Whenever I see a dive, I wonder whether it is purely instinctual or something teams practice together. And why not? Diving is a skill like any other.
Soccer does not have a diving problem because soccer players are uniquely shameless. It has a diving problem because the rewards are enormous, the punishment is rare, and billions of people have agreed to be complicit in the ruse.
Hedge knights · ↗ arxiv.org
How AI flattens public debate
Kim, Chang, Pham & Iyyer have a new paper on what they call argument collapse: the tendency of LLMs to produce arguments that converge on the same small set of perfectly reasonable, perfectly plausible, perfectly hedged points.
This is not surprising, of course. Humans actually believe shit, often to the point of unreason. For us, disagreements have stakes. We want the world to be one way and not another.
Maybe the future of public debate is an army of hedge knights, bravely sallying forth to defend the safest possible version of the argument.
As an aside, I was reminded of a recent column in El Espectador by Felipe Zuleta Lleras, or rather by Felipe Zuleta Lleras “and Gemini AI”. Zuleta says he posed a question to Gemini, agreed completely with the answer, and signed the result. The resulting electoral endorsement is not particularly hedged (quite the opposite, really). But still: if being a columnist means broadcasting your thoughts to others, what is the point of outsourcing the thought? The transparency is good, I guess. But whence cometh the columnist?
Hat tip to Yekyung Kim (the lead author) on Twitter.
Yes, you can fill XFA PDFs on Linux · ↗ linuxconfig.org
How to install the Windows version of Adobe Reader on Linux
If you’ve ever had to fill out a digital form for the Canadian government, there’s a good chance you’ve come across an XFA PDF. These are essentially fancy fillable forms with features like validation, dynamic fields, and barcode generation. But if you’re a Linux user, you’ve probably seen this message instead:
If this message is not eventually replaced by the proper contents of the document, your PDF viewer may not be able to display this type of document.
You can upgrade to the latest version of Adobe Reader for Windows®, Mac, or Linux® by visiting http://www.adobe.com/go/reader_download.
Adobe may respect the Linux trademark, but they don’t respect Linux users. Adobe Reader for Linux was abandoned in 2013. So what’s a guy living in the eternal year of the Linux desktop to do?
Let’s consider our options. Alternative PDF readers? No. Chrome? Nope. Firefox? It can open the files but not save any of the changes. The online Adobe Reader? Nope. Adobe mobile apps? Nope! It’s only Adobe Reader for desktop. But the Linux version is so old it no longer appears on Adobe’s website.
The solution? Use Wine to run the Windows version, of course! The website linuxconfig.org provides a nice tutorial on how to do just this. I can confirm that it works, at least on my Pop!_OS 22.04 install.
…Will the real <user> please stand up? · ↗ role-confusion.github.io
Prompt injection as role confusion
Ye, Cui & Hadfield-Menell wrote up their recent preprint on the mechanisms behind prompt injections as a highly readable blog post. Their argument is that prompt injection is best understood as a kind of role confusion. LLMs are supposed to distinguish between the different types of input using role tags (<user>, <system>, <think>, <tool>, and the like). But role tags can also be inserted maliciously, so LLMs seem to rely partly on the style of the text to infer what role it belongs to.
Unfortunately, this means that a webpage that sounds enough like an instruction can start to get treated like one. The conclusion of the paper is not very reassuring. If the model is always partly guessing who is speaking, then prompt injection may be less a problem we solve than a problem we learn to manage badly.
Hat tip to Simon Willison.
Seed hacking · ↗ arxiv.org
Optimizing the randomness out of your results
By now, p-hacking is a familiar research vice. It can be done with varying degrees of intent, from the naive beginner poking around in their data to the celebrity professor who makes a career of it. Basically, p-hacking occurs when researchers turn their datasets upside down and shake them until p < 0.05 falls out. This is generally accomplished by slicing the data in different ways, adding and removing variables, and running different kinds of tests until statistical significance is achieved. Usually it is accompanied with a healthy dose of selective reporting and HARKing (Hypothesizing After the Results are Known).
Less often discussed is seed hacking (or seed optimization/selection/scanning), as described in the humorously titled paper “torch.manual seed(3407) is all you need: On the influence of random seeds in deep learning architectures for computer vision” by David Picard. Basically, Picard built models on two of the classic datasets in computer vision (CIFAR and ImageNet), varying only the seed between training runs. He found that while overall variability between seeds was low, he could find “lucky” seeds that produced increases in validation accuracy that would be considered important improvements in the research community, despite being entirely due to luck. He concludes:
I am definitely not saying that all recent publications in computer vision are the result of lucky seed optimization. This is clearly not the case, these methods work. However, in the light of this short study, I am inclined to believe that many results are overstated due to implicit seed selection - be it from common experimental practice of trial and error or of the “evolutionary pressure” that peer review exerts on them.
…
Mapping the decline of local news · ↗ localnewsresearchproject.ca
Who watches city hall when the newspaper leaves town?
Local journalism in Canada is dying. When a local paper closes, municipal government gets easier to ignore. There is no one paid to sit through council meetings, read the zoning agenda, or call the mayor’s office when something looks off. Decisions just seem to happen.
The Local News Research Project has been tracking the decline for years now. Between 2008 and April 2026, over 600 local news outlets closed across nearly 400 communities in Canada.
The project is a collaboration led by April Lindgren of the Toronto Metropolitan University’s School of Journalism and Jon Corbett of the University of British Columbia’s Spatial Information for Community Mapping Lab. Their full crowdsourced database of events related to local newspapers, such as instances of papers closing, opening, merging, or moving online, is also available from their Local News Map data report page.
I first came across the project a little over three years ago, when I wrote an op-ed in The Globe and Mail (unpaywalled link) arguing for accessible video of municipal proceedings to help overworked local journalists find stories with the help of AI tools.
Love in lockdown · ↗ pudding.cool
Data journalism is alive and well.
Alvin Chang has a lovely new piece in The Pudding about what the pandemic did to American relationships. It is based on “How Couples Meet and Stay Together”, the Stanford survey by Michael Rosenfeld, Reuben Thomas, and Sonia Hausen, which followed couples in 2017, 2020, and 2022.
One of the piece’s main conclusions is that the pandemic widened existing gaps: strong relationships often got stronger, while weaker ones were more likely to deteriorate. I suppose this pattern repeated itself across other domains, such as the huge wealth gains that flowed to the already wealthy during the same period.
It is a remarkably engaging piece of data journalism, with little claymation figurines scrambling to rearrange themselves with every story beat.
There are some caveats. The stylish data presentation uses absolute numbers rather than relative proportions, which can occasionally make it hard to see some of the relationships being described. It also obscures some of the more sophisticated analysis behind the piece, which uses survey weights rather than raw counts. The main visualization only includes participants who were reached at all three time points, which was about half of the original sample. The original manuscript this paper is based on accounts for attrition using survey weights, and argues that attrition is not an important source of bias in any case.
…How a First Nation built what Vancouver wouldn’t · ↗ www.worksinprogress.news
Anya Martin has a great piece in Works in Progress about how the Squamish Nation reclaimed 11.7 acres of land in Vancouver and decided to build a huge housing development on it, called Senakw. The project will eventually add 6,000 rental homes for roughly 9,000 people, representing seven percent of all projected new housing in the city by 2033. Because the project is built on reserve land, it is exempt from zoning laws that constrain development in the rest of the region. With a loan from the Canada Mortgage and Housing Corporation and support from the City of Vancouver to connect public amenities, the project’s eleven towers will rise on land where almost any comparable private development would have been slowed, shrunk, or killed outright. Squamish Nation members voted to approve the development in 2019; unlike most neighbours asked to accept new housing, they had a direct stake in saying yes.
Away message: Quantifying the bias against null results in academic publishing · ↗ osf.io
This interesting paper from social scientist Ryan Briggs and colleagues attempts to quantify the widely believed bias against the publication of null results using a dataset of 100,000 articles published in political science journals. Here is a snippet of the abstract (emphasis mine):
In this article, we use large language models to extract granular and validated data on about 100,000 articles published in over 150 political science journals from 2010 to 2024. We show that fewer than 2% of articles that rely on statistical methods report null-only findings in their abstracts, while over 90% of papers highlight significant results. To put these findings in perspective, we develop and calibrate a simple model of publication bias. Across a range of plausible assumptions, we find that statistically significant results are estimated to be one to two orders of magnitude more likely to enter the published record than null results. Leveraging metadata extracted from individual articles, we show that the pattern of strong SoS holds across sub-fields, journals, methods, and time periods. However, a few factors such as pre-registration and randomized experiments correlate with greater acceptance of null results.
A depressing story for science but maybe a feel-good story for meta-science?
Away message: Data aquarium · ↗ dataaquarium.com
Spot the weird fish
Economist Justin Diamond created The Data Aquarium to visualize datasets as fish in an aquarium after being inspired by this thread about Chernoff faces. Apparently, the brain is much better at understanding multivariate data when variables are mapped to physical cues we are primed to recognize. Like faces, or in this case, fish in an aquarium. Spot the weird fish, spot the outlier!
Away message: GDP numbers in low-income countries are usually fake · ↗ davidoks.blog
This piece is a great follow-up to David Oks’s previous piece, “A lot of population numbers are fake”, which was the subject of my first post to this blog.
Away message: If you let AI do your writing for you… · ↗ samkriss.substack.com
This post from Sam Kriss…uh, discouraging people from passing off AI writing as their own is pretty damn funny.

Away message: Simulate how populations will change in the 21st century · ↗ ourworldindata.org
The excellent Our World in Data published a tool for simulating international population trends by 2030, 2050, and 2100 under different assumptions for fertility rates, life expectancy, and net migration rates.
Their default settings for Canada put us at 49 million by 2100 (compared to 53 million under UN projections), not even 10 million above our current total of around 41 million. And not even halfway to the goal articulated by the Century Initiative and the book Maximum Canada: Toward a Country of 100 Million.
Away message: The hallmarks of pseudoscience · ↗ www.mcgill.ca
In this article, Jonathan Jarry of McGill University’s Office for Science and Society offers up a kind of typology for pseudoscience.
We need a better class of billionaire
Andrew Carnegie was the godfather of modern philanthropy. His greatest gift to the world was the Carnegie library: thousands of them, many still standing today. I’ve been to several, dotted across Southwestern Ontario, where I grew up. I’ve seen his portrait still hanging.
Carnegie was also one of the modern world’s first billionaires, a ruthless steel tycoon whose company used armed guards and state militias to break striking workers. And yet his civic legacy is one you can physically stand in.
Compare that with men like Elon Musk and Jeff Bezos, representatives of today’s billionaire class. Their vision for humanity is grand and cosmic: the settlement of space, the survival of the species, the destiny of humanity. But they leave little room for the scale of everyday life.
A new generation of AI billionaires is coming. Nan Ransohoff argues that the technology could unlock hundreds of billions of dollars in new philanthropic capital, perhaps $37–100B per year if current trends hold. That is a lot of money to give away.
Most of this money will come from a milieu infused with rationalism and effective altruism. It is natural to be skeptical of a movement that treats personally accumulating as much wealth as possible as an optimal way to do good in the world. “Earning to give” is an awkward philosophy for a world where private fortunes have already achieved escape velocity. It also does not help that the figure most people now associate with EA is Sam Bankman-Fried.
…Has CRAN avoided malicious packages?
It seems that every week we read about another compromised package uploaded to PyPI or npm. The tide has become so steady that package managers are starting to implement dependency cooldowns. As a heavy R user, I began to wonder, has a malicious actor ever uploaded a compromised/malicious package to CRAN (the standard repository for R packages)?
I can’t think of any, and a Google search only turns up this weird thread on the R mailing list of an apparent false positive on a vignette bundled with a particular package. Thankfully, there is arXiv paper uploaded last year that directly addresses this question: A Time Series Analysis of Malware Uploads to Programming Language Ecosystems by Ruohonen & Saddiqa. This paper analyzes the Open Source Vulnerabilities (OSV) database for six popular programming language ecosystems: CRAN (R), Go, Maven (Java), npm (JavaScript), PyPI (Python), and RubyGems (Ruby).
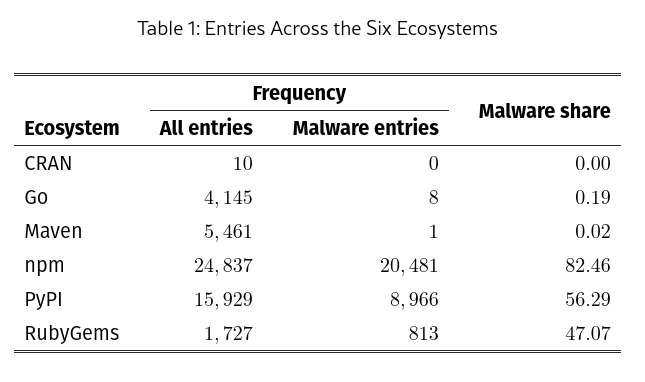
Table 1 from the paper shows CRAN to be completely free of malware entries, with Maven having only 1 and Go having 8. RubyGems has nearly a thousand and npm and PyPI have many thousands each. This is not to say packages uploaded to CRAN have never had vulnerabilities: the OSV database currently lists 14 for CRAN packages. But there is no evidence that any of these vulnerabilities were introduced with malicious intent.
…The war on statistical noise · ↗ www.commerce.gov
The US Department of Commerce bans differential privacy in its statistical products
The US Department of Commerce recently announced new rules governing disclosure avoidance in statistical products from the Census Bureau and the Bureau of Economic Analysis. They are banning noise infusion (a differential privacy technique) in favour of coarsening, or suppression as a last resort:
a. Coarsening shall be the preferred category of Disclosure Avoidance methods for all statistical products. b. Suppression shall be permitted as a last resort, only to be used when coarsening is prohibited by law or would substantially defeat the accuracy or usability of a statistical product. c. Noise infusion shall not be used for any statistical product.
Noise infusion preserves granularity by distorting values in a mathematically controlled way. The new preferred solution is simpler: provide less detail through aggregation and rounding. You can make the case for either method, though differential privacy techniques at least make the trade-offs more measurable.
I find the politics of this a bit mysterious (is differential privacy woke now?). The technical case against noise infusion is obvious enough: its use in the 2020 Census was legitimately controversial, particularly for the smallest geographies. But this justifies caution, not a wholesale ban. A categorical prohibition sends a message, even if I’m not quite sure what it is.
LLMs are great at giving the expected shape of an answer
Sometimes a shape is only a mirage.
This article from epidemiologist Adam Kucharski describes a neat sanity check he conducted on Microsoft Copilot. In the first experiment, he simulated 2,000 free text responses and labelled them “US”. Next, he copy and pasted these responses and labelled them “UK”. He then randomized the order and passed the combined dataset to Copilot to analyze. In the second experiment, he simulated 200 free text responses but copy and pasted them five times, assigning five different country labels to the otherwise identical datasets before again passing them to Copilot.
In both experiments, Copilot returned a deep analysis of the differences in how participants from each country responded to the prompts. The only problem, of course, is that the responses were identical between all countries: there were no actual differences to describe.
Instead, Copilot leaned on cultural stereotypes to give the expected shape of an answer. This should not be surprising; indeed, the only thing LLMs can do is give the expected shape of an answer. The surprising thing is that these answer-shaped responses are correct and useful as often as they are.
Of course, some will object to the use of Microsoft Copilot, a famously weak and outdated model. But Copilot is a widely deployed enterprise tool, and so for many users it will be their primary exposure to AI in a work context. In this experiment, Copilot was asked, using default settings, to perform a task it is explicitly advertised as being capable of doing. Defaults are powerful, and such an insidious failure mode is sure to cause harm, especially in the hands of ordinary users who lack the understanding and intuition to detect the common failure modes of these AI systems.
…Bananas are berries · ↗ www.mcgill.ca
It is fairly well known that tomatoes are culinary vegetables but botanical fruit. Somewhat less well known is that fruits like raspberries, strawberries, and blackberries are not berries, because they do not develop from a single flower containing one ovary. (For example, the yellow “seeds” on the exterior of the strawberry are the true fruit of the plant.) This article by Ada McVean and Cassandra Lee for McGill’s Office for Science and Society relays an even less well-known fact: bananas are berries, botanically speaking, since they are fleshy fruits developing from a single flower containing one ovary. As are cucumbers, pumpkins, lemons, avocados, watermelons, and grapes.
At least blueberries are, in fact, berries.
Apparently all of this recently came to a head when one angry Tesco shopper in the UK was denied his or her bonus points for purchasing berries. Reportedly, neither bananas nor strawberries were valid for the offer, meaning the store was applying neither the common definition for berries nor the botanical one.
Taxonomy is always interesting. As a biology major, I especially enjoyed cladistics, which offers up surprising conclusions like “birds are reptiles”, “birds are also dinosaurs”, and “fish are not a coherent group”. It reminds us that the categories we use to navigate the world are often practical rather than natural—and that nature, when asked to sort itself neatly, tends to shrug.
…Dragon Age: Origins is still really good
I replayed Dragon Age: Origins and its DLCs on PC about a year and a half ago, and it still slaps.
Let’s start with the obvious: the cover art is awesome. Iconic. My favourite cover art of any video game.

Actually, the game’s soundtrack has an even better version of the cover art.
{kind=link}
The music is also great, especially its GOATed title track by composer Inon Zur. Imagine being a high schooler firing up a new game and being greeted with that. RPG players talk about being stuck on the character creation screen, but that music kept me glued to the main menu.
I still like the graphics, too. I know they are “ugly”, but they are ugly in a way I find comforting. DA:O belonged to the last era of gaming before graphical fidelity basically saturated and every big-budget game started to look the same. It wears its dark fantasy pretensions in various shades of brown and sprays of blood. It looks like 2009 in the best possible way.
Of course, good presentation means little for an RPG if the world is boring or the characters are unlikable. Thankfully, DA:O works because it is so completely unselfconscious about being a dark fantasy RPG, and the characters are better for it. They are prickly, well-voiced, and rooted in the setting. Each character carries a piece of the world without being reduced to it.
…Snow in June
Daydream / I fell asleep amid the flowers / For a couple of hours / On a beautiful day
—Wallace Collection, “Daydream”
Every year in Montreal, sometime between late May and early June, it snows—sometimes for days on end. The flakes come from the cottonwood poplar (Populus deltoides). Get anywhere near one and the air fills with tiny seeds carried by long, silky threads.
Of course logistic regression is regression (and other fake categories)
I recently came across this article “Is logistic regression regression?” by data scientist Richard Vale. The post is a response to an apparent view in the machine learning community that “logistic regression” is a misnomer, because it is used for classification problems (with categorical outcomes), not regression problems (with real-valued outcomes).
As someone who learned statistics before machine learning, by way of biology and then epidemiology, this question would never have occurred to me. I was taught to group models by outcome type—logistic regression for binary outcomes, linear regression for continuous outcomes, multinomial regression for unordered categorical outcomes, Cox regression for time-to-event outcomes, and so on. Of course logistic regression is regression. It is regression with a binary outcome and a logit link. And besides (as Vale points out), logistic regression does not output a category label. Its raw output is log-odds, which may be transformed into a probability. “Classification” is a separate step layered on top, usually by imposing a threshold of 0.5.
This point goes to the statisticians.
I was not taught to think in terms of two types of predictive modelling: regression and classification. In fact, I’m not sure I ever came across the term “classification” until I picked up The Elements of Statistical Learning (okay, it was actually An Introduction to Statistical Learning). Rather, I was taught to approach modelling based on what I was trying to achieve: the type of research question. In this framework, there are three basic types of questions: descriptive (how are things distributed?), predictive (what outcome can we expect?), and causal (what difference would an exposure/intervention make?).
…Remembering J. Craig Venter (1946–2026) · ↗ en.wikipedia.org
J. Craig Venter, the ornery, fiercely competitive genomics pioneer, died earlier this year at the age of 79. In the late 1990s, he launched Celera Genomics to challenge the publicly funded Human Genome Project, betting that with enough computing power, whole-genome shotgun sequencing would beat the public project’s more careful map-first approach. In 2000, he stood next to Francis Collins and Bill Clinton as the rival public and private efforts jointly announced their draft sequences of the human genome. Ten years later, his team would announce the creation of the first self-replicating bacterial cell controlled by a synthetic genome. His brash, controversial style made him emblematic of an ascendant, disruptive biotech industry, but won him few friends in the scientific establishment.
My mom picked up his memoir A Life Decoded for me to read in high school. Obviously, it stuck with me, and was probably one of the many reasons I decided to study biology and evolution in undergrad.
For better or worse, Venter made biology feel more like a battlefield than a body of settled knowledge.
AI love and Good Will Hunting
I was listening to Ezra Klein’s latest interview with Yuval Noah Harari and was interested by the section on AI relationships (emphasis mine):
HARARI: AIs, which are experts in pretending to be conscious entities that have feelings for you. And it’s relatively easy for them to do it because maybe the most important way for people to kind of build relationships is language. So, you know, when an AI tells you, I love you. It’s not like a science fiction movie from the 1960s when it does so in a very cold, mechanic way and doesn’t really understand what love is. No, it does so in the most seductive voice possible. And then when you ask the AI, do you really love me? Do you even know what love means?
The AI can give you the most amazing description of how love feels like because it has mastered language and it has read All the best love poems in history, all the psychology books about love, all the blogs, it’s have seen all the Hollywood blockbusters about love. It can describe love better than almost any human poet or psychologist or lover.
KLEIN: In this respect, it’s able to sever language from meaning. […] When an AI says, I love you, it does not mean what it means when a human says, I love you. There’s not an I behind that.
…
Biosecurity in the land of Chinese peptides · ↗ www.wired.com
Yesterday, leaders across AI, biotech, and national security signed on to an open letter calling for laws requiring companies selling synthetic DNA/RNA to screen customers and orders to prevent misuse.
Much has been said about AI as an enabling technology for guerilla bioterrorism (or biological warfare by state actors, for that matter). I definitely believe the magnitude of this threat is underrated by the general public.
But this is Silicon Valley we’re talking about, where the grey-market purchasing of sketchy “Chinese peptides” is rampant and normalized. They know better than anyone that these laws will be, at best, a speedbump to a motivated domestic terrorist, even if they might help curb casual misuse. And this is to say nothing of actors outside the reach of American regulators.